pacman::p_load(sf, tidyverse, tmap, spatstat, raster, sparr)Take Home Exercise 1
Geospatial analytics offer valuable insights into the patterns of armed conflict, enabling better understanding and response strategies. This study focuses on armed conflict events in Myanmar from January 2021 to June 2024, using data from the Armed Conflict Location & Event Data (ACLED) project. The analysis examines the spatial and temporal distribution of four key event types: Battles, Explosion/Remote Violence, Strategic Developments, and Violence Against Civilians. By investigating quarterly data, this study aims to reveal patterns in the conflict, contributing to a deeper understanding of the ongoing violence in Myanmar.
To start off, let’s begin by importing all the necessary libraries:
Now that we have done so, let’s load the necessary combat data from ACLED (note that due to API limitations I am only able to get data from a certain starting date):
conflict_data <- read_csv("data/2021-08-31-2024-06-30-Myanmar.csv")Rows: 41275 Columns: 31
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (20): event_id_cnty, event_date, disorder_type, event_type, sub_event_ty...
dbl (11): year, time_precision, inter1, inter2, interaction, iso, latitude, ...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.list(conflict_data)[[1]]
# A tibble: 41,275 × 31
event_id_cnty event_date year time_precision disorder_type event_type
<chr> <chr> <dbl> <dbl> <chr> <chr>
1 MMR64313 30 June 2024 2024 1 Political violence Battles
2 MMR64320 30 June 2024 2024 1 Political violence Battles
3 MMR64321 30 June 2024 2024 1 Political violence Battles
4 MMR64322 30 June 2024 2024 1 Strategic develop… Strategic…
5 MMR64323 30 June 2024 2024 1 Political violence Battles
6 MMR64324 30 June 2024 2024 1 Strategic develop… Strategic…
7 MMR64325 30 June 2024 2024 1 Political violence Battles
8 MMR64326 30 June 2024 2024 1 Political violence Battles
9 MMR64328 30 June 2024 2024 1 Political violence Battles
10 MMR64330 30 June 2024 2024 1 Political violence Battles
# ℹ 41,265 more rows
# ℹ 25 more variables: sub_event_type <chr>, actor1 <chr>, assoc_actor_1 <chr>,
# inter1 <dbl>, actor2 <chr>, assoc_actor_2 <chr>, inter2 <dbl>,
# interaction <dbl>, civilian_targeting <chr>, iso <dbl>, region <chr>,
# country <chr>, admin1 <chr>, admin2 <chr>, admin3 <chr>, location <chr>,
# latitude <dbl>, longitude <dbl>, geo_precision <dbl>, source <chr>,
# source_scale <chr>, notes <chr>, fatalities <dbl>, tags <chr>, …We have the latitude and longitude of event locations. We need to convert them into SFOs such that we can work with them using the sf library. Additionally, we need to normalise the dates such that they are all standardised into the same format that is computer readable.
conflict_data <- conflict_data %>% st_as_sf(coords = c("longitude", "latitude"), crs = 4326) %>% st_transform(crs = 32647) %>% mutate(event_date = dmy(event_date))
list(conflict_data)[[1]]
Simple feature collection with 41275 features and 29 fields
Geometry type: POINT
Dimension: XY
Bounding box: xmin: -208804.4 ymin: 1103500 xmax: 640934.5 ymax: 3042960
Projected CRS: WGS 84 / UTM zone 47N
# A tibble: 41,275 × 30
event_id_cnty event_date year time_precision disorder_type event_type
* <chr> <date> <dbl> <dbl> <chr> <chr>
1 MMR64313 2024-06-30 2024 1 Political violence Battles
2 MMR64320 2024-06-30 2024 1 Political violence Battles
3 MMR64321 2024-06-30 2024 1 Political violence Battles
4 MMR64322 2024-06-30 2024 1 Strategic developme… Strategic…
5 MMR64323 2024-06-30 2024 1 Political violence Battles
6 MMR64324 2024-06-30 2024 1 Strategic developme… Strategic…
7 MMR64325 2024-06-30 2024 1 Political violence Battles
8 MMR64326 2024-06-30 2024 1 Political violence Battles
9 MMR64328 2024-06-30 2024 1 Political violence Battles
10 MMR64330 2024-06-30 2024 1 Political violence Battles
# ℹ 41,265 more rows
# ℹ 24 more variables: sub_event_type <chr>, actor1 <chr>, assoc_actor_1 <chr>,
# inter1 <dbl>, actor2 <chr>, assoc_actor_2 <chr>, inter2 <dbl>,
# interaction <dbl>, civilian_targeting <chr>, iso <dbl>, region <chr>,
# country <chr>, admin1 <chr>, admin2 <chr>, admin3 <chr>, location <chr>,
# geo_precision <dbl>, source <chr>, source_scale <chr>, notes <chr>,
# fatalities <dbl>, tags <chr>, timestamp <dbl>, geometry <POINT [m]>Now that we have the armed conflict data, let’s import the administrative boundary data:
boundaries <- st_read("data", layer = "mmr_polbnda2_adm1_250k_mimu_1")Reading layer `mmr_polbnda2_adm1_250k_mimu_1' from data source
`/home/tropicbliss/GitHub/quarto-project/Take-home_Ex/Take-home_Ex01/data'
using driver `ESRI Shapefile'
Simple feature collection with 18 features and 6 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 92.1721 ymin: 9.696844 xmax: 101.17 ymax: 28.54554
Geodetic CRS: WGS 84st_crs(boundaries)Coordinate Reference System:
User input: WGS 84
wkt:
GEOGCRS["WGS 84",
DATUM["World Geodetic System 1984",
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]],
ID["EPSG",6326]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8901]],
CS[ellipsoidal,2],
AXIS["geodetic longitude",east,
ORDER[1],
ANGLEUNIT["degree",0.0174532925199433]],
AXIS["geodetic latitude",north,
ORDER[2],
ANGLEUNIT["degree",0.0174532925199433]]]This is currently in WGS84, and we need to convert it into a projected coordinate system so we can work with the data.
boundaries <- boundaries %>% st_transform(crs = 32647)
st_crs(boundaries)Coordinate Reference System:
User input: EPSG:32647
wkt:
PROJCRS["WGS 84 / UTM zone 47N",
BASEGEOGCRS["WGS 84",
ENSEMBLE["World Geodetic System 1984 ensemble",
MEMBER["World Geodetic System 1984 (Transit)"],
MEMBER["World Geodetic System 1984 (G730)"],
MEMBER["World Geodetic System 1984 (G873)"],
MEMBER["World Geodetic System 1984 (G1150)"],
MEMBER["World Geodetic System 1984 (G1674)"],
MEMBER["World Geodetic System 1984 (G1762)"],
MEMBER["World Geodetic System 1984 (G2139)"],
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]],
ENSEMBLEACCURACY[2.0]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4326]],
CONVERSION["UTM zone 47N",
METHOD["Transverse Mercator",
ID["EPSG",9807]],
PARAMETER["Latitude of natural origin",0,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8801]],
PARAMETER["Longitude of natural origin",99,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8802]],
PARAMETER["Scale factor at natural origin",0.9996,
SCALEUNIT["unity",1],
ID["EPSG",8805]],
PARAMETER["False easting",500000,
LENGTHUNIT["metre",1],
ID["EPSG",8806]],
PARAMETER["False northing",0,
LENGTHUNIT["metre",1],
ID["EPSG",8807]]],
CS[Cartesian,2],
AXIS["(E)",east,
ORDER[1],
LENGTHUNIT["metre",1]],
AXIS["(N)",north,
ORDER[2],
LENGTHUNIT["metre",1]],
USAGE[
SCOPE["Engineering survey, topographic mapping."],
AREA["Between 96°E and 102°E, northern hemisphere between equator and 84°N, onshore and offshore. China. Indonesia. Laos. Malaysia - West Malaysia. Mongolia. Myanmar (Burma). Russian Federation. Thailand."],
BBOX[0,96,84,102]],
ID["EPSG",32647]]A horrifying amount, most of which seems to be clustered at the interior of Myanmar. Let’s overlay an administrative district map to see where most of them are all located at:
map1 <- tm_shape(boundaries) +
tm_fill() +
tm_borders() +
tm_text("ST", size = 0.2, col = "blue")
map2 <- tm_shape(boundaries) +
tm_fill() +
tm_borders() +
tm_shape(conflict_data) +
tm_dots()
tmap_arrange(map1, map2, ncol = 2)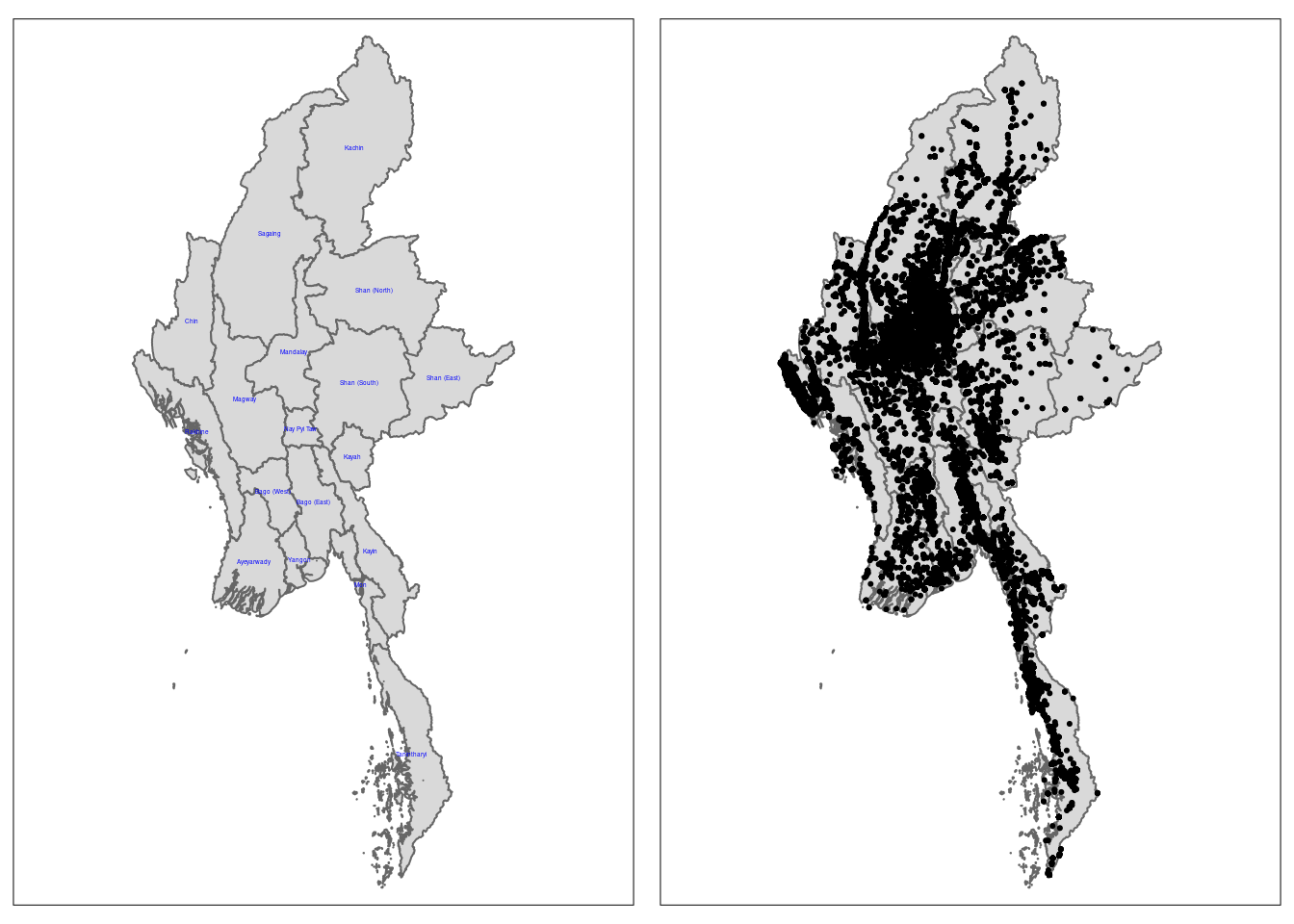
Quarterly KDE analysis
Now we are going to apply Kernel Density Estimation (KDE) to conflict events for each quarter of the year. These layers show the density of events over a geographic area, which can help visualize how the concentration of those events changes over time, particularly on a quarterly basis. However, to do that we need to choose an appropriate year to observe the by-quarterly results. After much deliberation I have chose 2022 as the best year for this, and here’s why:
The coup started in February 2021. While it might be interesting to analyse the slow growth in conflicts over time, the data is not representative of the Myanmar conflict as a whole.
In 2022, the political and military landscape had largely stabilized after the initial shock of the coup in 2021. The armed resistance led by various ethnic armed organizations (EAOs) and the People’s Defense Forces (PDFs) was more organized and widespread. Of course, despite the apparent stabilization in 2022, the situation remains volatile. The junta’s crackdown on dissent, targeted killings, and the increasing involvement of ethnic armed organisations have contributed to ongoing instability.
Data extraction and filtering
Extracting conflict data by quarter:
conflict_data_2022_q1 <- conflict_data %>% filter(event_date >= as.Date("2022-01-01") & event_date <= as.Date("2022-03-31"))
conflict_data_2022_q2 <- conflict_data %>% filter(event_date >= as.Date("2022-04-01") & event_date <= as.Date("2022-06-30"))
conflict_data_2022_q3 <- conflict_data %>% filter(event_date >= as.Date("2022-07-01") & event_date <= as.Date("2022-09-30"))
conflict_data_2022_q4 <- conflict_data %>% filter(event_date >= as.Date("2022-10-01") & event_date <= as.Date("2022-12-31"))Data conversion
::: {.callout-note}
The bandwidth in the context of KDE is a critical parameter that determines the level of smoothing applied to the data when estimating the density. It controls how much each data point influences the estimate of the density around it.
:::conflict_data_2022_q1_ppp <- as.ppp(conflict_data_2022_q1)Warning in as.ppp.sf(conflict_data_2022_q1): only first attribute column is
used for marksconflict_data_2022_q2_ppp <- as.ppp(conflict_data_2022_q2)Warning in as.ppp.sf(conflict_data_2022_q2): only first attribute column is
used for marksconflict_data_2022_q3_ppp <- as.ppp(conflict_data_2022_q3)Warning in as.ppp.sf(conflict_data_2022_q3): only first attribute column is
used for marksconflict_data_2022_q4_ppp <- as.ppp(conflict_data_2022_q4)Warning in as.ppp.sf(conflict_data_2022_q4): only first attribute column is
used for marksplot(conflict_data_2022_q1_ppp)Warning in default.charmap(ntypes, chars): Too many types to display every type
as a different characterWarning: Only 10 out of 4267 symbols are shown in the symbol map
summary(conflict_data_2022_q1_ppp)Marked planar point pattern: 4267 points
Average intensity 2.785283e-09 points per square unit
Coordinates are given to 13 decimal places
marks are of type 'character'
Summary:
Length Class Mode
4267 character character
Window: rectangle = [-204784, 591875.9] x [1103500.1, 3026504.9] units
(796700 x 1923000 units)
Window area = 1.53198e+12 square unitsMany statistical methods in spatial point pattern analysis are based on the assumption that the underlying point process is simple. A simple point process means that no two points in the process can occupy the exact same location (i.e., they cannot be coincident).
If points are coincident, this assumption is violated, and the statistical methods that rely on this assumption may produce invalid or misleading results.
Thus, let’s check if there are any duplicate points:
any(duplicated(conflict_data_2022_q1_ppp))[1] FALSEany(duplicated(conflict_data_2022_q2_ppp))[1] FALSEany(duplicated(conflict_data_2022_q3_ppp))[1] FALSEany(duplicated(conflict_data_2022_q4_ppp))[1] FALSEAs you can see, there doesn’t seem to be any duplicated data points.
Next, we need to create an owin object. This helps to confine the analysis within a specific geographical area.
boundaries_owin <- as.owin(boundaries)plot(boundaries_owin)
As, you can see, the owin object contains state boundaries, which we don’t need. We need to find a way to dissolve those state boundaries.
myanmar_sf <- st_union(boundaries)plot(myanmar_sf)
Still not that good. Luckily the website also contain geographical data that does not include state lines.
national_boundaries <- st_read("data", layer = "mmr_polbnda_adm0_250k_mimu_1") %>% st_transform(crs = 32647)Reading layer `mmr_polbnda_adm0_250k_mimu_1' from data source
`/home/tropicbliss/GitHub/quarto-project/Take-home_Ex/Take-home_Ex01/data'
using driver `ESRI Shapefile'
Simple feature collection with 1 feature and 2 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 92.1721 ymin: 9.696844 xmax: 101.17 ymax: 28.54554
Geodetic CRS: WGS 84st_crs(boundaries)Coordinate Reference System:
User input: EPSG:32647
wkt:
PROJCRS["WGS 84 / UTM zone 47N",
BASEGEOGCRS["WGS 84",
ENSEMBLE["World Geodetic System 1984 ensemble",
MEMBER["World Geodetic System 1984 (Transit)"],
MEMBER["World Geodetic System 1984 (G730)"],
MEMBER["World Geodetic System 1984 (G873)"],
MEMBER["World Geodetic System 1984 (G1150)"],
MEMBER["World Geodetic System 1984 (G1674)"],
MEMBER["World Geodetic System 1984 (G1762)"],
MEMBER["World Geodetic System 1984 (G2139)"],
ELLIPSOID["WGS 84",6378137,298.257223563,
LENGTHUNIT["metre",1]],
ENSEMBLEACCURACY[2.0]],
PRIMEM["Greenwich",0,
ANGLEUNIT["degree",0.0174532925199433]],
ID["EPSG",4326]],
CONVERSION["UTM zone 47N",
METHOD["Transverse Mercator",
ID["EPSG",9807]],
PARAMETER["Latitude of natural origin",0,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8801]],
PARAMETER["Longitude of natural origin",99,
ANGLEUNIT["degree",0.0174532925199433],
ID["EPSG",8802]],
PARAMETER["Scale factor at natural origin",0.9996,
SCALEUNIT["unity",1],
ID["EPSG",8805]],
PARAMETER["False easting",500000,
LENGTHUNIT["metre",1],
ID["EPSG",8806]],
PARAMETER["False northing",0,
LENGTHUNIT["metre",1],
ID["EPSG",8807]]],
CS[Cartesian,2],
AXIS["(E)",east,
ORDER[1],
LENGTHUNIT["metre",1]],
AXIS["(N)",north,
ORDER[2],
LENGTHUNIT["metre",1]],
USAGE[
SCOPE["Engineering survey, topographic mapping."],
AREA["Between 96°E and 102°E, northern hemisphere between equator and 84°N, onshore and offshore. China. Indonesia. Laos. Malaysia - West Malaysia. Mongolia. Myanmar (Burma). Russian Federation. Thailand."],
BBOX[0,96,84,102]],
ID["EPSG",32647]]national_boundaries_owin <- as.owin(national_boundaries)plot(national_boundaries_owin)
That’s much better. We simply need to combine the ppp and the owin objects.
conflictMYQ1_ppp <- conflict_data_2022_q1_ppp[national_boundaries_owin]
conflictMYQ2_ppp <- conflict_data_2022_q2_ppp[national_boundaries_owin]
conflictMYQ3_ppp <- conflict_data_2022_q3_ppp[national_boundaries_owin]
conflictMYQ4_ppp <- conflict_data_2022_q4_ppp[national_boundaries_owin]plot(conflictMYQ1_ppp)Warning in default.charmap(ntypes, chars): Too many types to display every type
as a different characterWarning: Only 10 out of 4267 symbols are shown in the symbol map
crs_info <- st_crs(national_boundaries)
unit_of_measurement <- crs_info$units
print(unit_of_measurement)[1] "m"First, we need to convert the unit of measurement to kilometres since the density values would be too small to comprehend.
conflictMYQ1_ppp.km <- rescale.ppp(conflictMYQ1_ppp, 1000, "km")
conflictMYQ2_ppp.km <- rescale.ppp(conflictMYQ2_ppp, 1000, "km")
conflictMYQ3_ppp.km <- rescale.ppp(conflictMYQ3_ppp, 1000, "km")
conflictMYQ4_ppp.km <- rescale.ppp(conflictMYQ4_ppp, 1000, "km")Working with different bandwidth methods
bw.CvL(conflictMYQ1_ppp.km) sigma
66.96841 bw.scott(conflictMYQ1_ppp.km) sigma.x sigma.y
33.58016 77.84496 bw.ppl(conflictMYQ1_ppp.km) sigma
4.298156 bw.diggle(conflictMYQ1_ppp.km) sigma
0.2187043 The sigma values for bw.diggle and bw.ppl seem way too small. A small sigma value might result in sudden spikes of the data over an extremely small area, which would not be useful when analysing such a large geographical area. Since the conflict data contains regions where points seem to be highly clustered, an automatic bandwidth selection method might select a smaller sigma to capture the fine structure in those areas. This can lead to undersmoothing across the entire dataset, making the density plot appear as many small bright spots with abrupt transitions.
kde_conflictMYQ1_scott <- density(conflictMYQ1_ppp.km, sigma=bw.scott, edge=TRUE, kernel="quartic")Warning in density.ppp(conflictMYQ1_ppp.km, sigma = bw.scott, edge = TRUE, :
Bandwidth selection will be based on Gaussian kernelkde_conflictMYQ1_CvL <- density(conflictMYQ1_ppp.km, sigma=bw.scott, edge=TRUE, kernel="quartic")Warning in density.ppp(conflictMYQ1_ppp.km, sigma = bw.scott, edge = TRUE, :
Bandwidth selection will be based on Gaussian kernelpar(mfrow=c(1,2))
plot(kde_conflictMYQ1_scott, main = "bw.scott")
plot(kde_conflictMYQ1_CvL, main = "bw.CvL")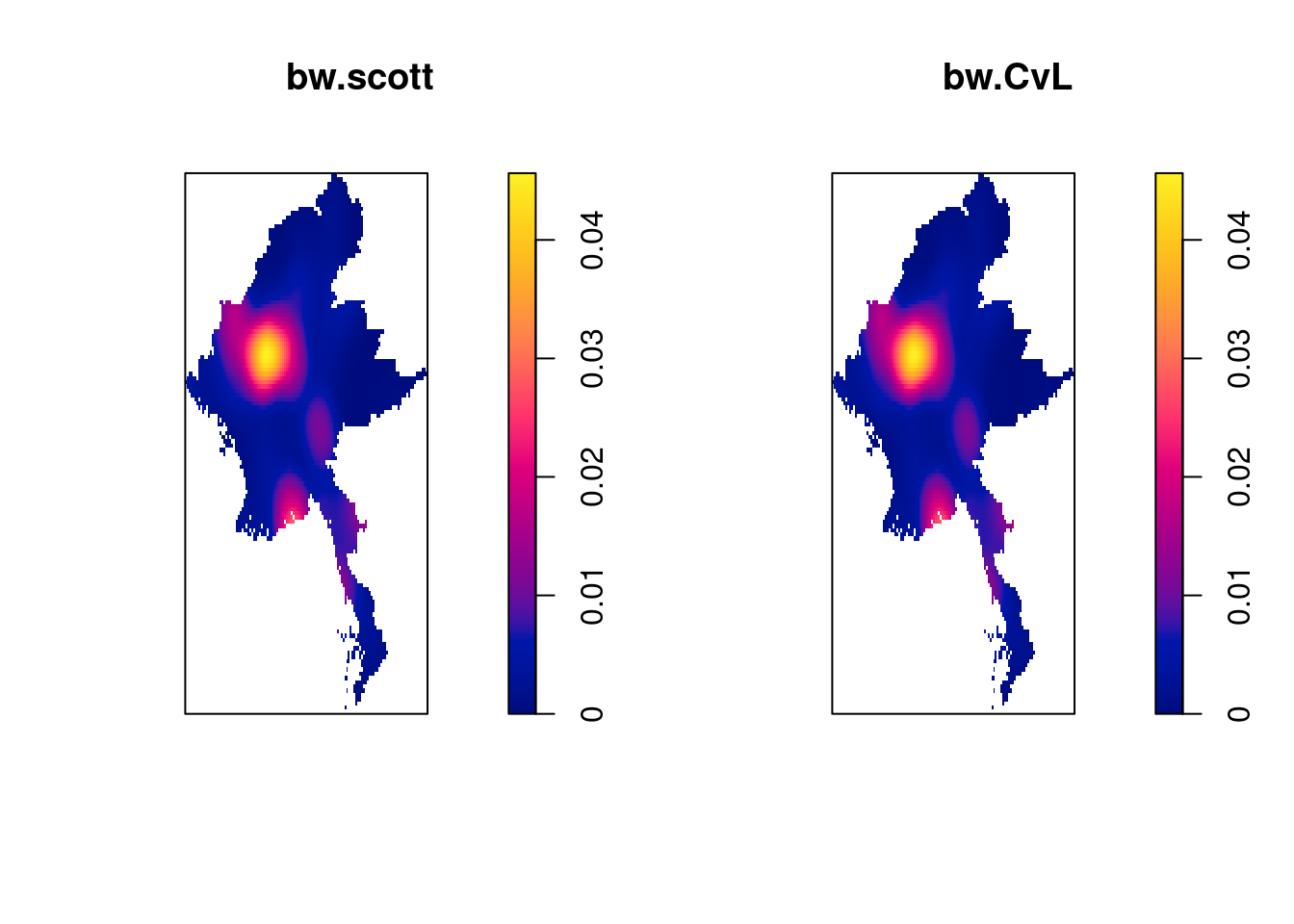
From trial and error, it seems like bw.scott is the best fit for our use case.
The edge parameter controls whether edge correction should be applied. Edge correction accounts for the fact that points near the boundaries of the observation window have fewer neighbors and, without correction, could lead to underestimation of density near the edges.Setting edge = TRUE ensures that edge correction is applied, which adjusts the density estimate near the borders to compensate for this bias.
To avoid negative intensity values, for kernel methods I will choose "quartic".
Plotting our results
Since we are analysing the same geographical area over a period of time, and we want to apply the same amount of smoothing, I am going to use the sigma value derived from the first quarter using bw.scott and apply it to all quarters.
kde_sigma <- bw.scott(conflictMYQ1_ppp.km)
kde_conflictMYQ1.bw <- density(conflictMYQ1_ppp.km, sigma=kde_sigma, edge=TRUE, kernel="quartic")
kde_conflictMYQ2.bw <- density(conflictMYQ2_ppp.km, sigma=kde_sigma, edge=TRUE, kernel="quartic")
kde_conflictMYQ3.bw <- density(conflictMYQ3_ppp.km, sigma=kde_sigma, edge=TRUE, kernel="quartic")
kde_conflictMYQ4.bw <- density(conflictMYQ4_ppp.km, sigma=kde_sigma, edge=TRUE, kernel="quartic")Next, I am going to convert this into a raster object to make it ggplot2 compatible, to make it easier to plot with:
kde_conflictMYQ1_raster <- raster(kde_conflictMYQ1.bw)
kde_conflictMYQ2_raster <- raster(kde_conflictMYQ2.bw)
kde_conflictMYQ3_raster <- raster(kde_conflictMYQ3.bw)
kde_conflictMYQ4_raster <- raster(kde_conflictMYQ4.bw)Let us take a look at the properties of the RasterLayers created.
kde_conflictMYQ1_rasterclass : RasterLayer
dimensions : 128, 128, 16384 (nrow, ncol, ncell)
resolution : 7.302001, 16.30032 (x, y)
extent : -210.0086, 724.6476, 1072.026, 3158.467 (xmin, xmax, ymin, ymax)
crs : NA
source : memory
names : layer
values : -2.353015e-17, 0.04563376 (min, max)Notice that the crs property is NA. We need to set it to an appropriate value.
projection(kde_conflictMYQ1_raster) <- CRS("+init=EPSG:32647 +units=km")
projection(kde_conflictMYQ2_raster) <- CRS("+init=EPSG:32647 +units=km")
projection(kde_conflictMYQ3_raster) <- CRS("+init=EPSG:32647 +units=km")
projection(kde_conflictMYQ4_raster) <- CRS("+init=EPSG:32647 +units=km")Now, it’s finally time to plot the data.
1st quarter
tm_shape(kde_conflictMYQ1_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE) +
tm_shape(boundaries) +
tm_text("ST", size = 0.3, col = "white")Legend labels were too wide. The labels have been resized to 0.61, 0.61, 0.61, 0.61, 0.61. Increase legend.width (argument of tm_layout) to make the legend wider and therefore the labels larger.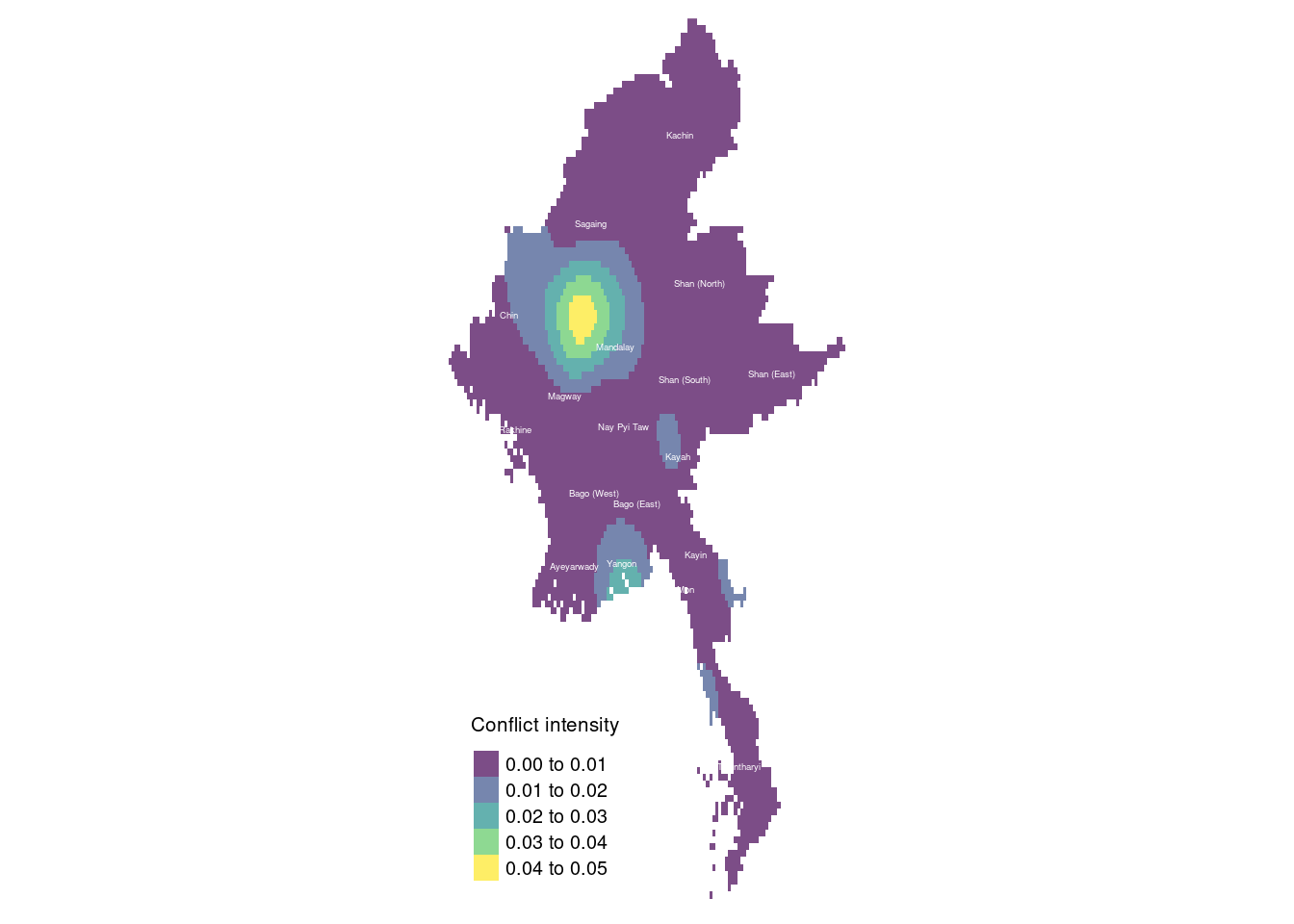
The map reveals that much of the conflict occurred in Sagaing and Magway, with localized fighting in Shan (South) and Kayah, and another significant hotspot in Yangon. This aligns with news reports indicating that during the first quarter of 2022, the Myanmar conflict was primarily concentrated in Rakhine, Chin, Sagaing, and Magway regions. Sagaing and Magway, in particular, saw numerous battles involving the People’s Defence Forces (PDF), while Chin State experienced substantial conflict due to its proximity to India and the presence of active ethnic insurgent groups. Meanwhile, Rakhine State remained a key battleground for clashes between the Arakan Army (AA) and the Tatmadaw.
Sagaing and Magway became strongholds for the PDF, local militias that formed in response to the military coup. These regions saw widespread opposition to military rule, with strong support for the armed struggle against the Tatmadaw. The terrain in Sagaing, in particular, provided resistance groups with strategic advantages for carrying out guerrilla-style attacks on military convoys and outposts.
Yangon, Myanmar’s largest city, also became a significant hotspot during this period. While most rural areas were engulfed in insurgency and military battles, urban resistance in Yangon consisted of sabotage operations, targeted assassinations, and bombings orchestrated by the PDF and other resistance groups. These attacks targeted military personnel, government officials, and infrastructure, making Yangon a focal point of urban conflict.
In Shan (South) and Kayah, localized conflicts arose due to territorial disputes and long-standing tensions. Both regions are home to multiple ethnic armed groups, and the fighting reflected ongoing struggles for control and autonomy in the area.
2nd quarter
tm_shape(kde_conflictMYQ2_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE) +
tm_shape(boundaries) +
tm_text("ST", size = 0.3, col = "white")Legend labels were too wide. The labels have been resized to 0.61, 0.61, 0.61, 0.61, 0.61. Increase legend.width (argument of tm_layout) to make the legend wider and therefore the labels larger.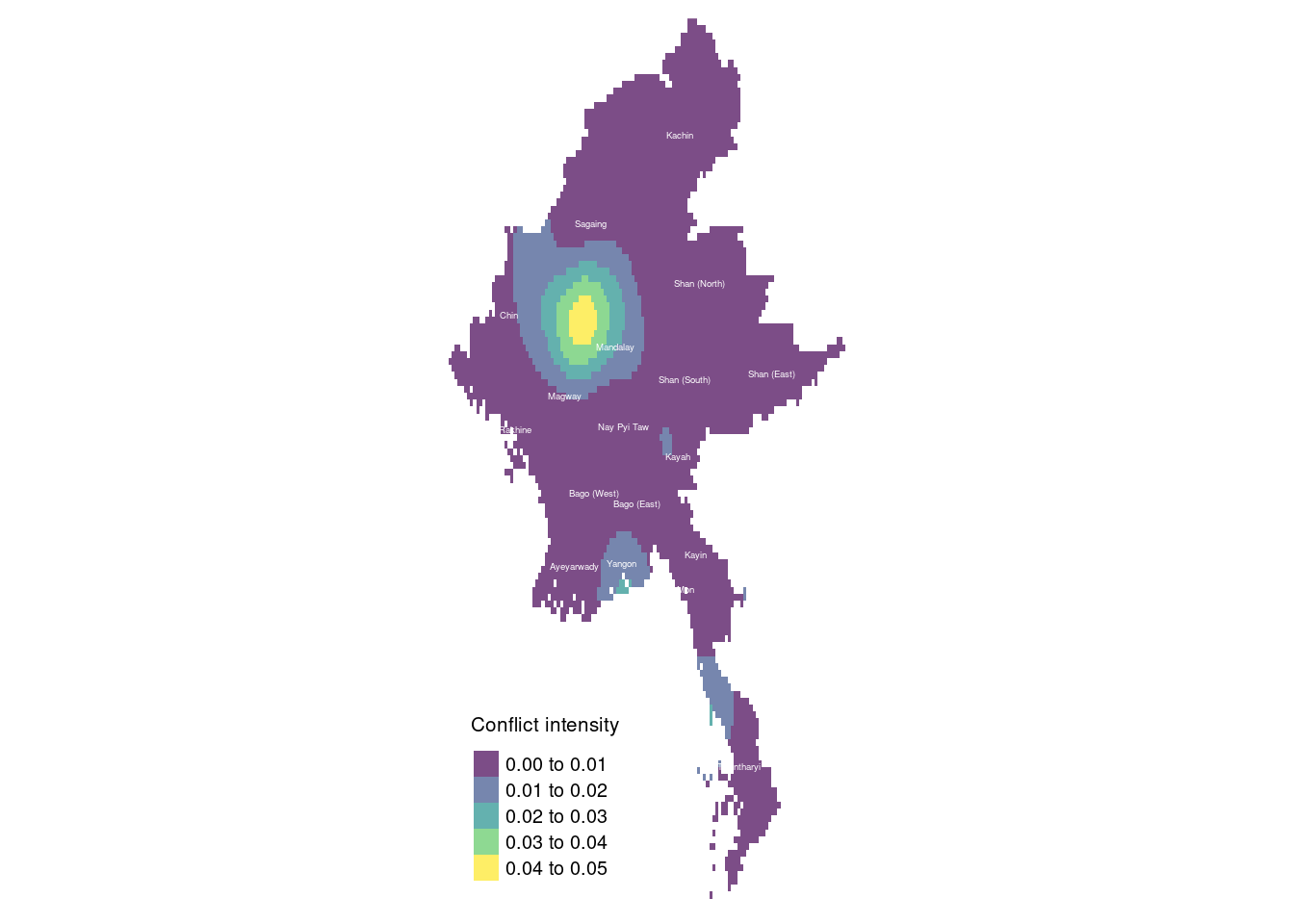
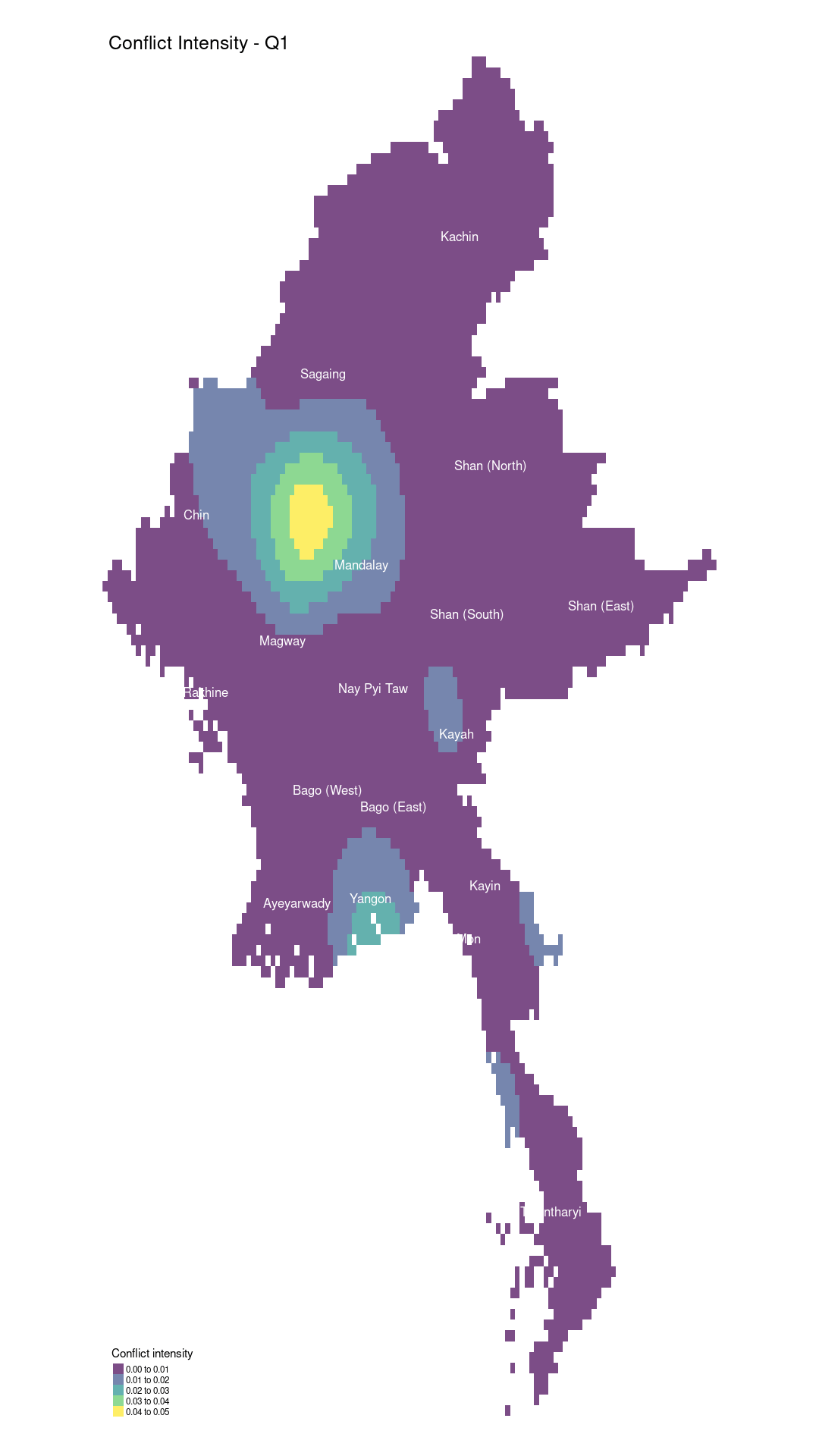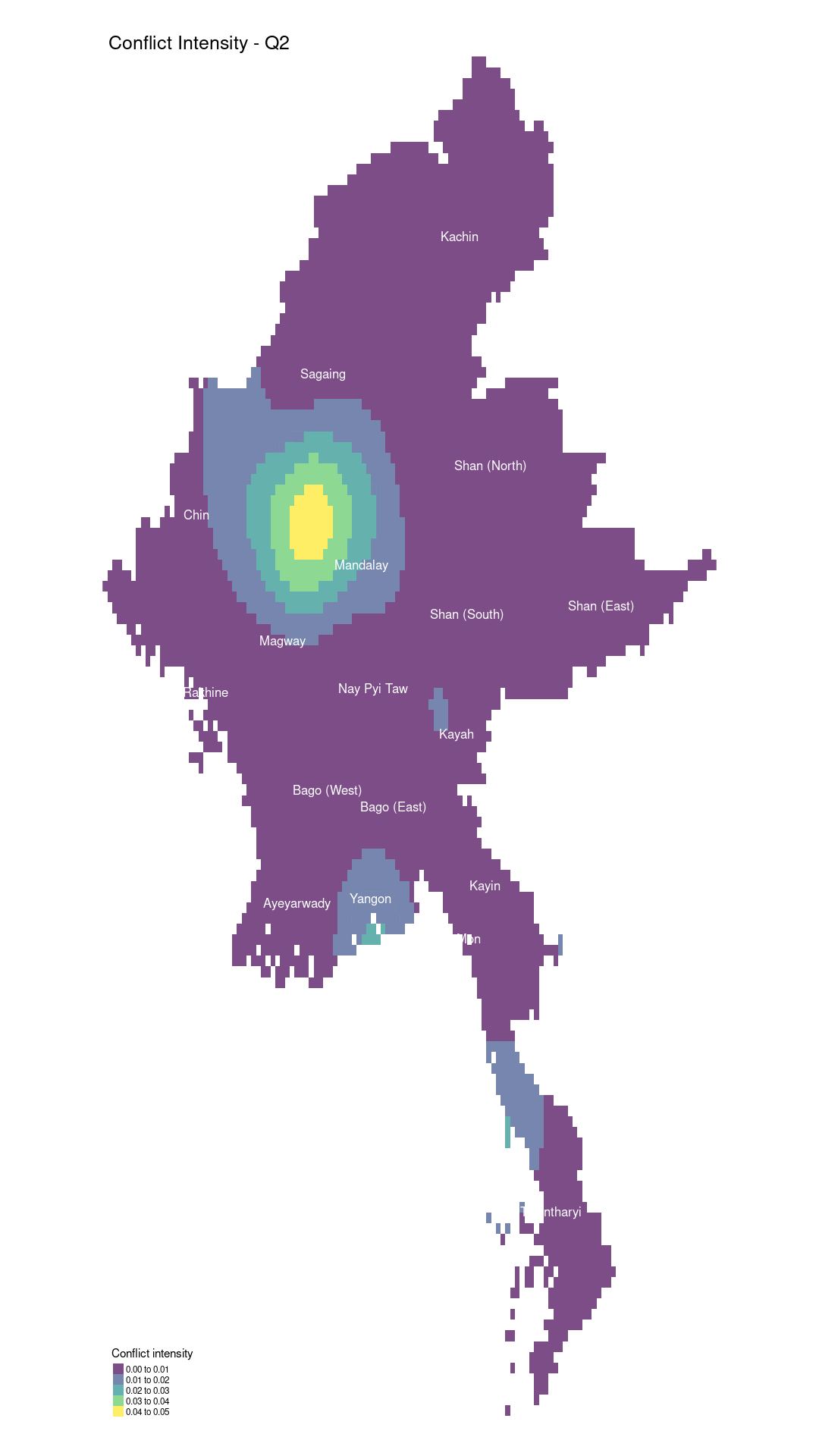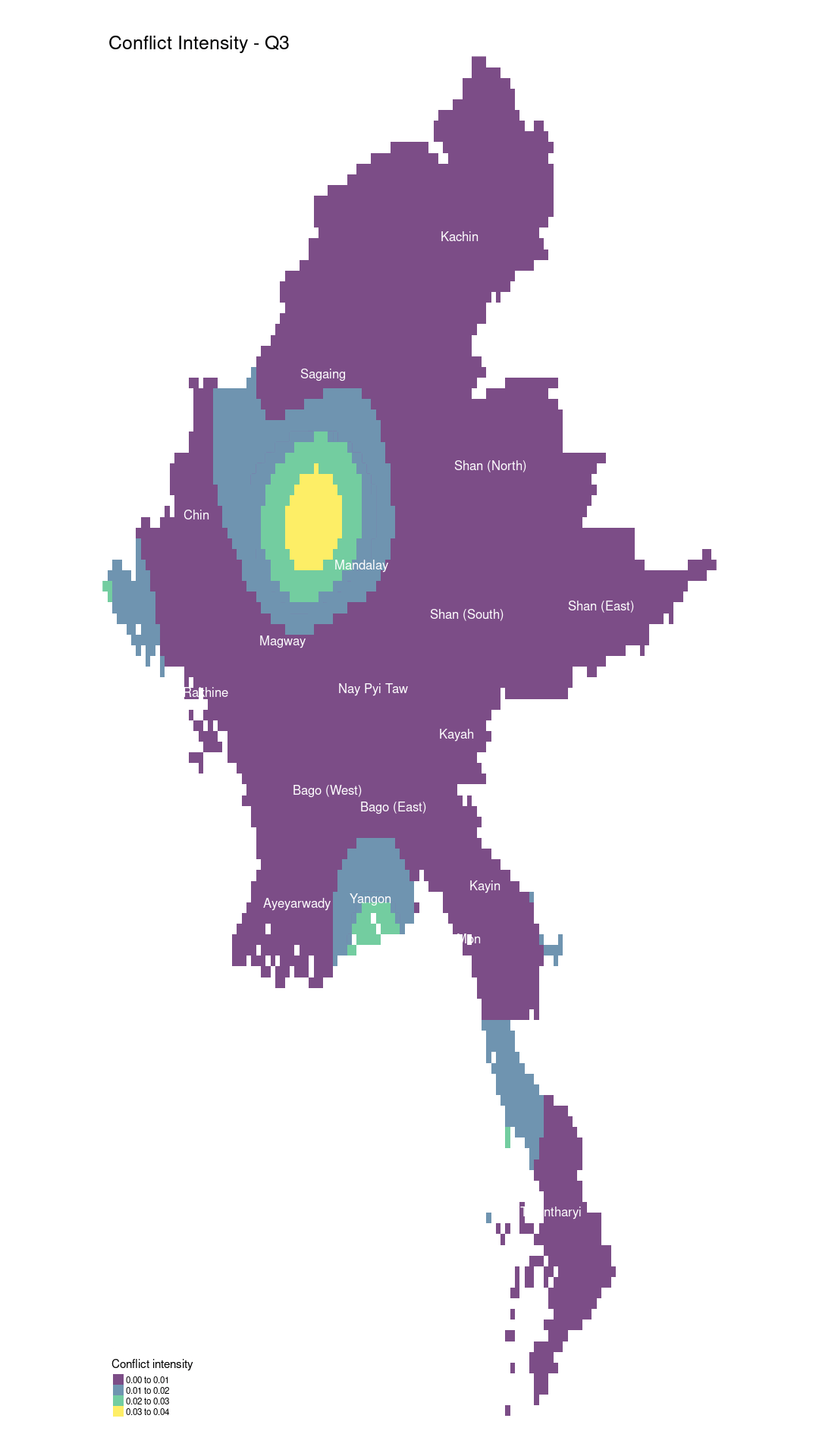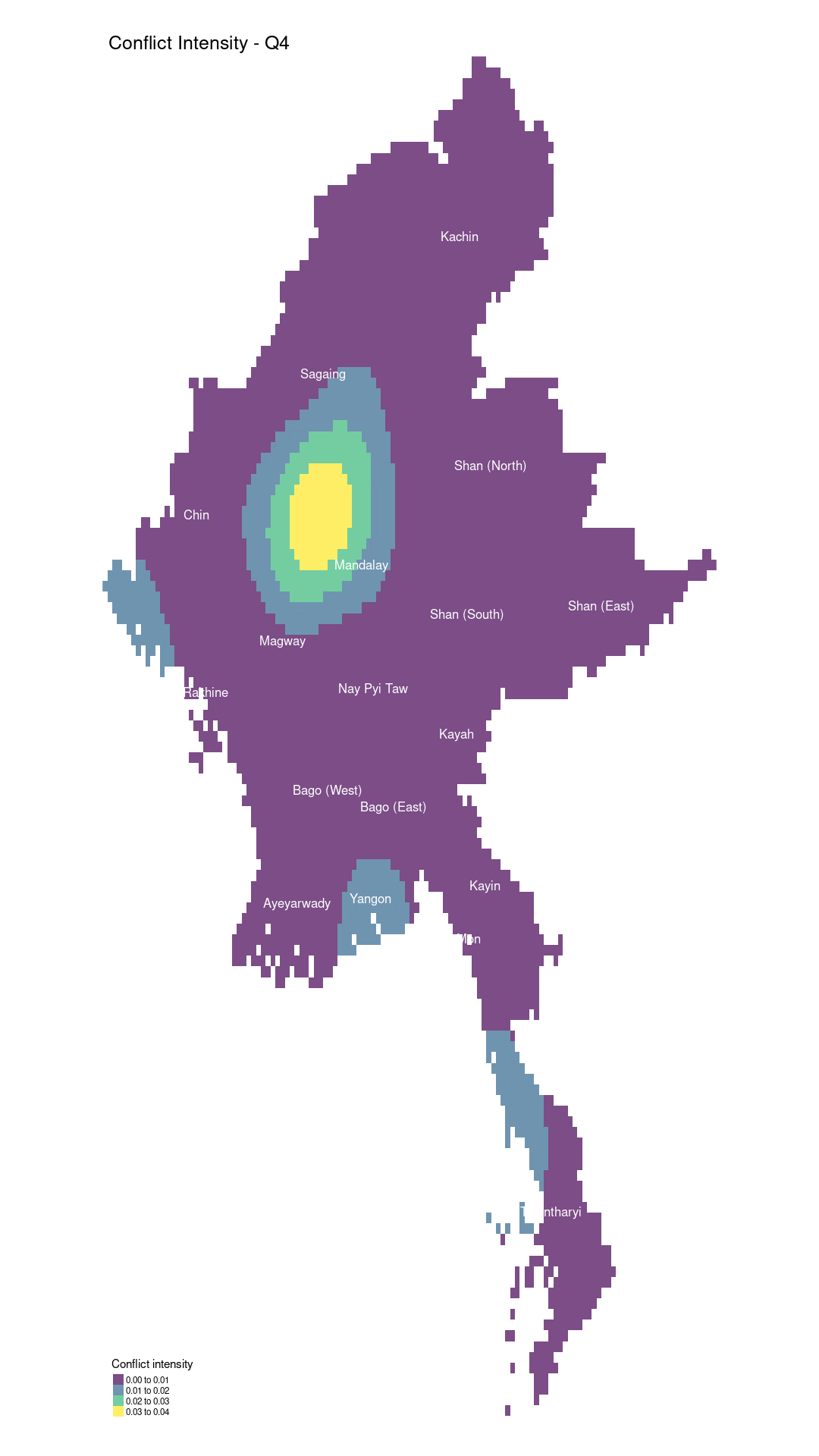
In the second quarter, fighting became more concentrated in Sagaing, Magway, and Chin State. In particular, the conflict in Chin State intensified as clashes escalated between the Tatmadaw and ethnic insurgent groups, including the Chin National Front (CNF) and local PDF forces. Chin State’s strategic location near the Indian border made it a key theater of conflict, prompting increased military offensives against insurgent strongholds. This led to more intense military operations and a rise in human rights abuses, such as arbitrary detentions and targeted attacks on civilians.
Meanwhile, conflict in Shan (South)/Kayah and Yangon showed signs of abating. The Tatmadaw redirected its focus to the more intense fighting in Sagaing, Magway, and Chin, which had become central battlegrounds due to the growing strength of the PDF. This shift likely reduced military pressure in Shan (South) and Kayah, contributing to the decline in conflict there. Additionally, reports of temporary ceasefires or negotiation efforts between the Tatmadaw and some ethnic armed organizations (EAOs) may have contributed to the decrease in reported conflicts, although these ceasefires are often fragile.
Tanintharyi experienced a rise in reported conflicts during the second quarter. Previously, this southern Myanmar region had been relatively less impacted by the conflict, but by quarter 2, it saw increased activity due to escalating resistance from local People’s Defence Forces (PDF) and clashes with the military. The region’s strategic coastal position and its proximity to Thailand likely played a role in its growing importance in the conflict.
3rd quarter
tm_shape(kde_conflictMYQ3_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE) +
tm_shape(boundaries) +
tm_text("ST", size = 0.3, col = "white")Legend labels were too wide. The labels have been resized to 0.61, 0.61, 0.61, 0.61. Increase legend.width (argument of tm_layout) to make the legend wider and therefore the labels larger.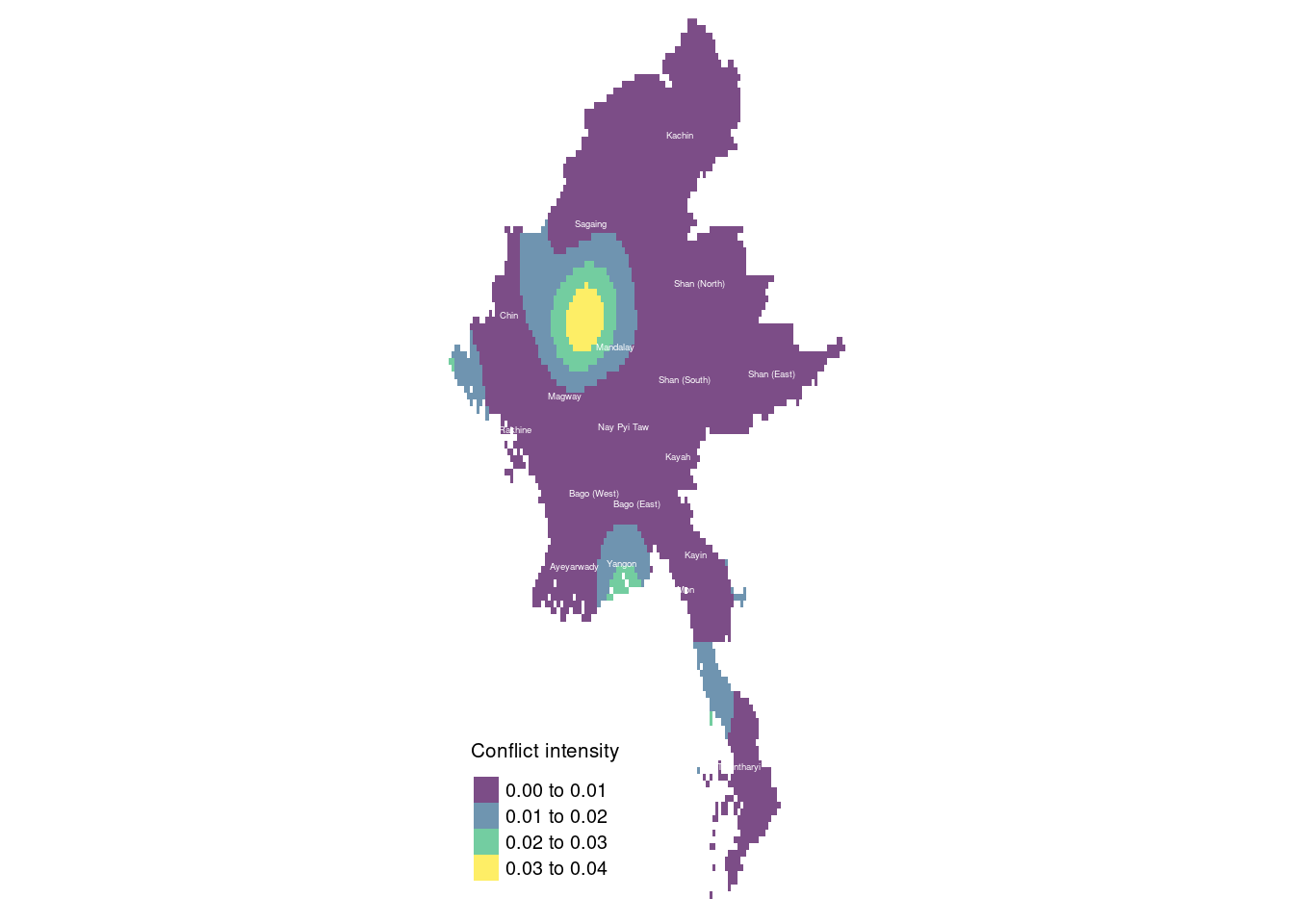
Between quarters 2 and 3, the conflict in Shan (South) and Kayah significantly decreased, while fighting in Yangon returned to the intensity seen in quarter 1. The People’s Defence Forces (PDF) and other resistance groups likely resumed urban operations, including sabotage, bombings, and targeted assassinations, directed at military personnel and government officials. This resurgence indicates a renewal of urban resistance despite heightened military crackdowns. Meanwhile, Rakhine State experienced a sharp rise in reported conflicts. The Arakan Army (AA) intensified its efforts against the Tatmadaw, seeking greater control over the region. The AA’s renewed activity led to more frequent clashes, with the fighting spreading to more densely populated areas, worsening the humanitarian crisis.
4th quarter
tm_shape(kde_conflictMYQ4_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE) +
tm_shape(boundaries) +
tm_text("ST", size = 0.3, col = "white")Legend labels were too wide. The labels have been resized to 0.61, 0.61, 0.61, 0.61. Increase legend.width (argument of tm_layout) to make the legend wider and therefore the labels larger.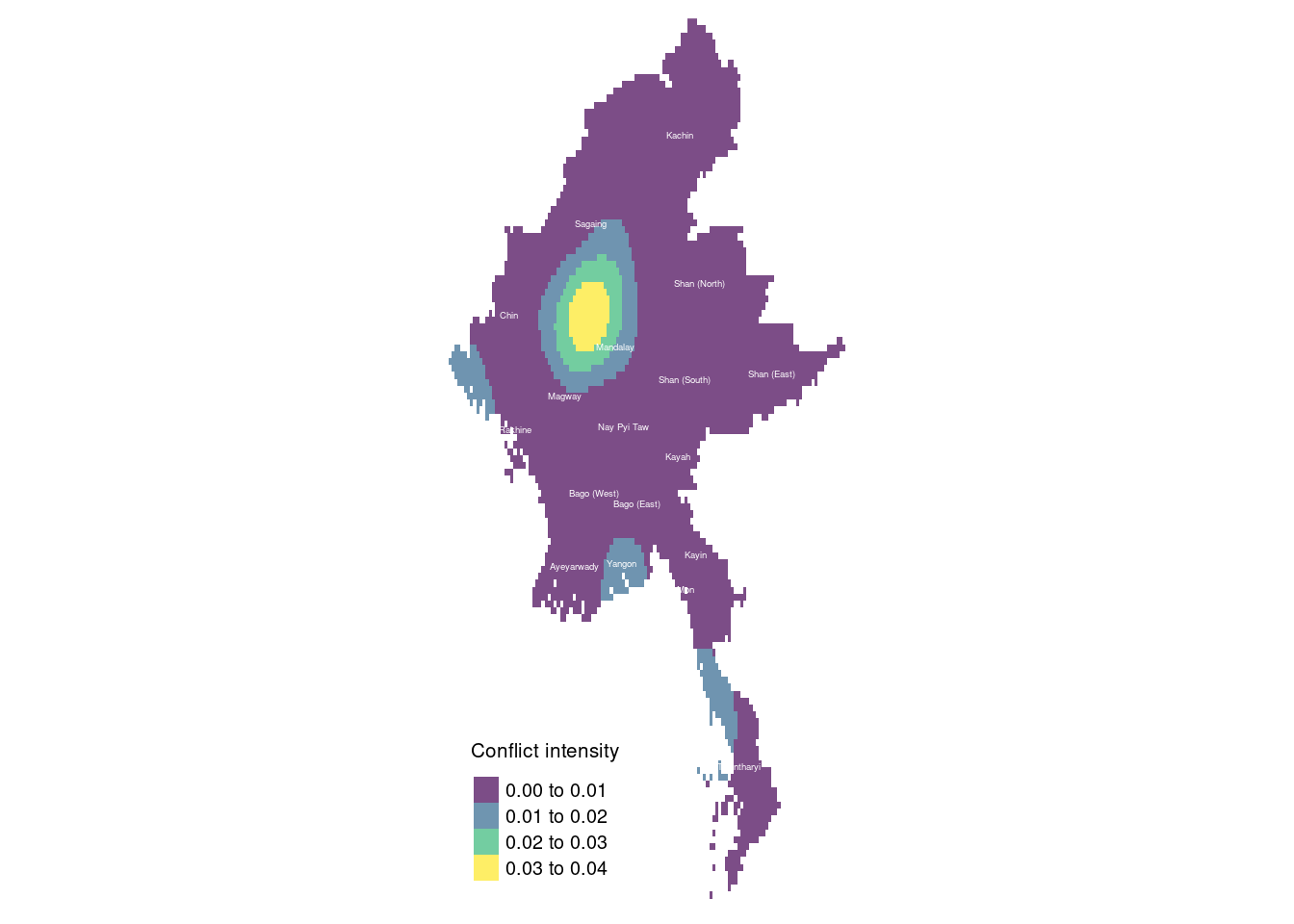
In quarter 4, fighting became more localized in Sagaing, while conflict in Chin State subsided. However, hostilities persisted in Rakhine, Yangon, and Tanintharyi.
In Sagaing, the fighting intensified and became more concentrated, likely due to the Tatmadaw’s increased efforts to suppress resistance forces, particularly in rural areas where the People’s Defence Forces (PDF) operated. The region’s terrain, which is conducive to guerrilla tactics, allowed resistance groups to continue their operations, despite the fighting being confined to specific pockets. The Tatmadaw may have redirected more resources to Sagaing, leading to a reduction in larger-scale battles elsewhere.
Earlier in the year, Chin State had experienced heavy fighting, but by quarter 4, both sides may have been experiencing resource exhaustion, resulting in a relative lull in conflict. The state’s terrain and its cross-border dynamics with India may have also contributed to the decrease in confrontations.
Rakhine State remained a key battleground, with ongoing clashes between the Arakan Army (AA) and the Tatmadaw. The AA’s growing strength and territorial ambitions fueled the conflict as they sought greater autonomy for the region. The Tatmadaw likely prioritized Rakhine due to its strategic importance along the Bay of Bengal.
Tanintharyi continued to witness fighting, largely due to its strategic location and the rising presence of resistance groups. Its proximity to the Thai border made the region a crucial area for supply routes and safe havens for resistance forces, resulting in sustained military clashes.
Summary
pacman::p_load(gifski)
q1_graph <- tm_shape(kde_conflictMYQ1_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE, main.title = "Conflict Intensity - Q1") +
tm_shape(boundaries) +
tm_text("ST", col = "white")
q2_graph <- tm_shape(kde_conflictMYQ2_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE, main.title = "Conflict Intensity - Q2") +
tm_shape(boundaries) +
tm_text("ST", col = "white")
q3_graph <- tm_shape(kde_conflictMYQ3_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE, main.title = "Conflict Intensity - Q3") +
tm_shape(boundaries) +
tm_text("ST", col = "white")
q4_graph <- tm_shape(kde_conflictMYQ4_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE, main.title = "Conflict Intensity - Q4") +
tm_shape(boundaries) +
tm_text("ST", col = "white")
tmap_animation(
list(q1_graph, q2_graph, q3_graph, q4_graph),
delay = 100,
filename = "raster_animation.gif",
width = 1080,
height = 1920
)
Since all the raster’s represent the same area in different periods of time, we are going to create a RasterStack to visualise the conflict over an OpenStreetMap view with tmap.
conflictMY_raster <- stack(kde_conflictMYQ1_raster, kde_conflictMYQ2_raster, kde_conflictMYQ3_raster, kde_conflictMYQ4_raster)
class(conflictMY_raster)[1] "RasterStack"
attr(,"package")
[1] "raster"tmap_mode("view")tmap mode set to interactive viewingtm_shape(conflictMY_raster) +
tm_raster("layer", palette = "viridis", title = "Conflict intensity", alpha = 0.7) +
tm_basemap("OpenStreetMap") +
tm_layout(legend.position = c("left", "bottom"), frame = FALSE)legend.postion is used for plot mode. Use view.legend.position in tm_view to set the legend position in view mode.Warning: col specification in tm_raster is ignored, since stars object contains
a 3rd dimension, where its values are used to create facetsTip: rasters can be shown as layers instead of facets by setting tm_facets(as.layers = TRUE).tmap_mode("plot")tmap mode set to plottingIs the conflict clustered or dispersed?
We can use Clark-Evans test to test for whether the distribution of conflicts is clustered or dispersed across Myanmar. This can help us understand the underlying patterns and drivers of conflict. If the conflict events are clustered in specific areas, it suggests the presence of hotspots driven by factors such as ethnic tensions, military strategies, or geographical advantages.
Since I am coming in with the notion that the distribution of conflicts are highly clustered. I am going to use a one-tailed Clark-Evans test. I am however not going to use edge correction for my test, as I personally feel that the study area is large enough that it is not sufficient to result in fewer neighbours along the boundaries. In fact, data so far has shown that that is in fact the opposite. Fighting seemed more intense in areas bordering India and Thailand.
The test hypotheses are:
Ho = The distribution of conflicts are randomly distributed (complete spatial randomness when R = 1).
H1= The distribution of conflicts are not randomly distributed (the events are clustered and closer together than expected under random distribution when R < 1).
The 95% confident interval will be used.
conflictMY_ppp <- superimpose(conflictMYQ1_ppp, conflictMYQ2_ppp, conflictMYQ3_ppp, conflictMYQ4_ppp)clarkevans.test(conflictMY_ppp,
correction="none",
clipregion="national_boundaries_owin",
alternative=c("clustered"),
nsim=99)
Clark-Evans test
No edge correction
Z-test
data: conflictMY_ppp
R = 0.16171, p-value < 2.2e-16
alternative hypothesis: clustered (R < 1)Since our R-value is less than 1, it indicates clustering. In this case, R = 0.16171, which is significantly less than 1, indicating that the conflicts are clustered.
The p-value represents the probability of observing such a clustered pattern under the null hypothesis of randomness. A p-value less than the significance level (α = 0.05) allows us to reject the null hypothesis. In this case, the p-value is extremely small (essentially zero), far below the 0.05 threshold.
Since R < 1 and the p-value is extremely small, we reject the null hypothesis.
This means we have strong evidence to conclude that the distribution of conflicts is not randomly distributed. Instead, the distribution is clustered. Conflicts tend to be closer together than what would be expected under a random spatial distribution.
2nd-order Spatial Point Patterns Analysis
To do our 2nd order spatial point analysis, let’s focus on the Sagaing, the state where the conflicts was the most fiercest in 2022.
conflict_data_2022_sagaing <- conflict_data %>% filter(admin1 == "Sagaing") %>% filter(year == 2022)
conflict_data_2022_sagaing_ppp <- as.ppp(conflict_data_2022_sagaing)Warning in as.ppp.sf(conflict_data_2022_sagaing): only first attribute column
is used for marksunitname(conflict_data_2022_sagaing_ppp)unit / units The unit of the ppp function has not been set. Let’s set it to metres based on the CRS.
unitname(conflict_data_2022_sagaing_ppp) <- c("metre", "metres")F-Function
The F function estimates the empty space function F(r) or its hazard rate h(r) from a point pattern in a window of arbitrary shape.
The F-function measures the cumulative distribution of distances from a random point in the study region to the nearest point in the point pattern. Essentially, it answers the question: “given a random location in the study area, what is the probability that the nearest point in the pattern is within a distance r”?
x-axis (r): Represents the distance from a random point in the study area to the nearest point in the pattern.
y-axis (F(r)): Represents the cumulative probability that the distance from a random location to the nearest point is less than or equal to
r.
F_Sagaing = Fest(conflict_data_2022_sagaing_ppp)
plot(F_Sagaing)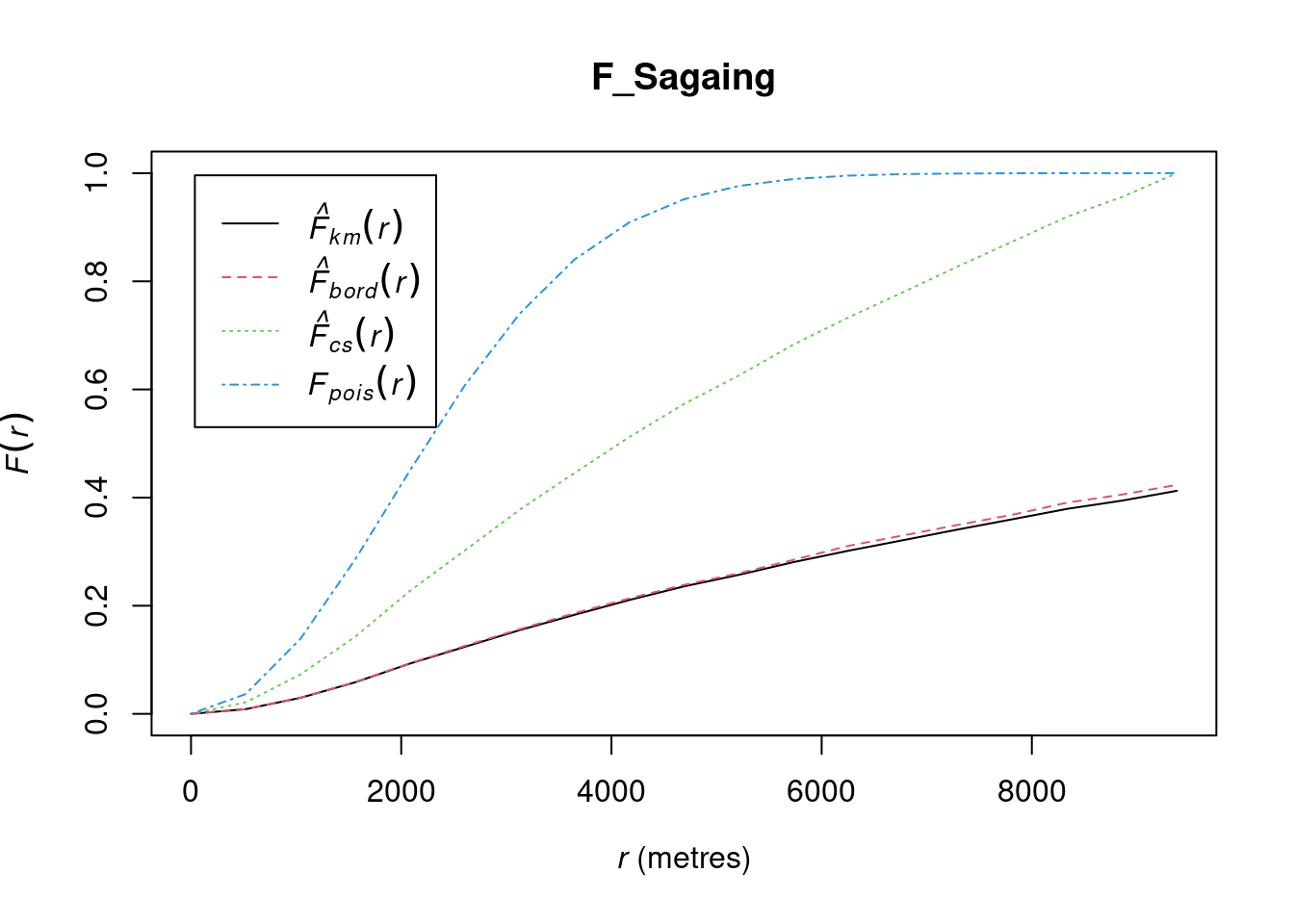
The solid line represents the empirical F-function (
F(r)), which shows the distribution of distances from random points in the study area to the nearest observed point.The dashed line represents the theoretical F-function under complete spatial randomness (CSR). This line helps you compare the observed point pattern to a random point distribution.
The small gradient in the F-function at short distances suggests that many random locations in the study area have no nearby conflict events. This implies that conflict events are sparse or dispersed at smaller scales.
Around the 2000-meter mark, the F-function shows a more linear increase, indicating that random locations start to have a consistent distance to the nearest conflict event. Beyond this point, events are regularly spaced, implying a more uniform distribution.
The initial slow rise suggests conflict events are far from random locations at small scales, while the linear rise beyond 2000 meters points to a consistent spacing pattern. This may reflect conflict clustering in specific areas, with gaps between them, and more predictable event proximity at larger distances.
Conflict events may be concentrated in specific areas like towns, military bases, or strategic locations, with gaps in between, resulting in regular spacing at a larger scale. At shorter distances, fewer events occur, indicating less frequent conflict, but beyond around 2000 meters, events become more consistently distributed.
Hypothesis testing
To confirm the observed spatial patterns above, a hypothesis test will be conducted. The hypothesis and test are as follows:
Ho = The distribution of conflicts at Sagaing are randomly distributed.
H1= The distribution of conflicts at Sagaing are not randomly distributed.
The null hypothesis will be rejected if p-value is smaller than alpha value of 0.001.
F_Sagaing.csr <- envelope(conflict_data_2022_sagaing_ppp, Fest, nsim = 999)Generating 999 simulations of CSR ...
1, 2, 3, ......10.........20.........30.........40.........50.........60..
.......70.........80.........90.........100.........110.........120.........130
.........140.........150.........160.........170.........180.........190........
.200.........210.........220.........230.........240.........250.........260......
...270.........280.........290.........300.........310.........320.........330....
.....340.........350.........360.........370.........380.........390.........400..
.......410.........420.........430.........440.........450.........460.........470
.........480.........490.........500.........510.........520.........530........
.540.........550.........560.........570.........580.........590.........600......
...610.........620.........630.........640.........650.........660.........670....
.....680.........690.........700.........710.........720.........730.........740..
.......750.........760.........770.........780.........790.........800.........810
.........820.........830.........840.........850.........860.........870........
.880.........890.........900.........910.........920.........930.........940......
...950.........960.........970.........980.........990........
999.
Done.plot(F_Sagaing.csr)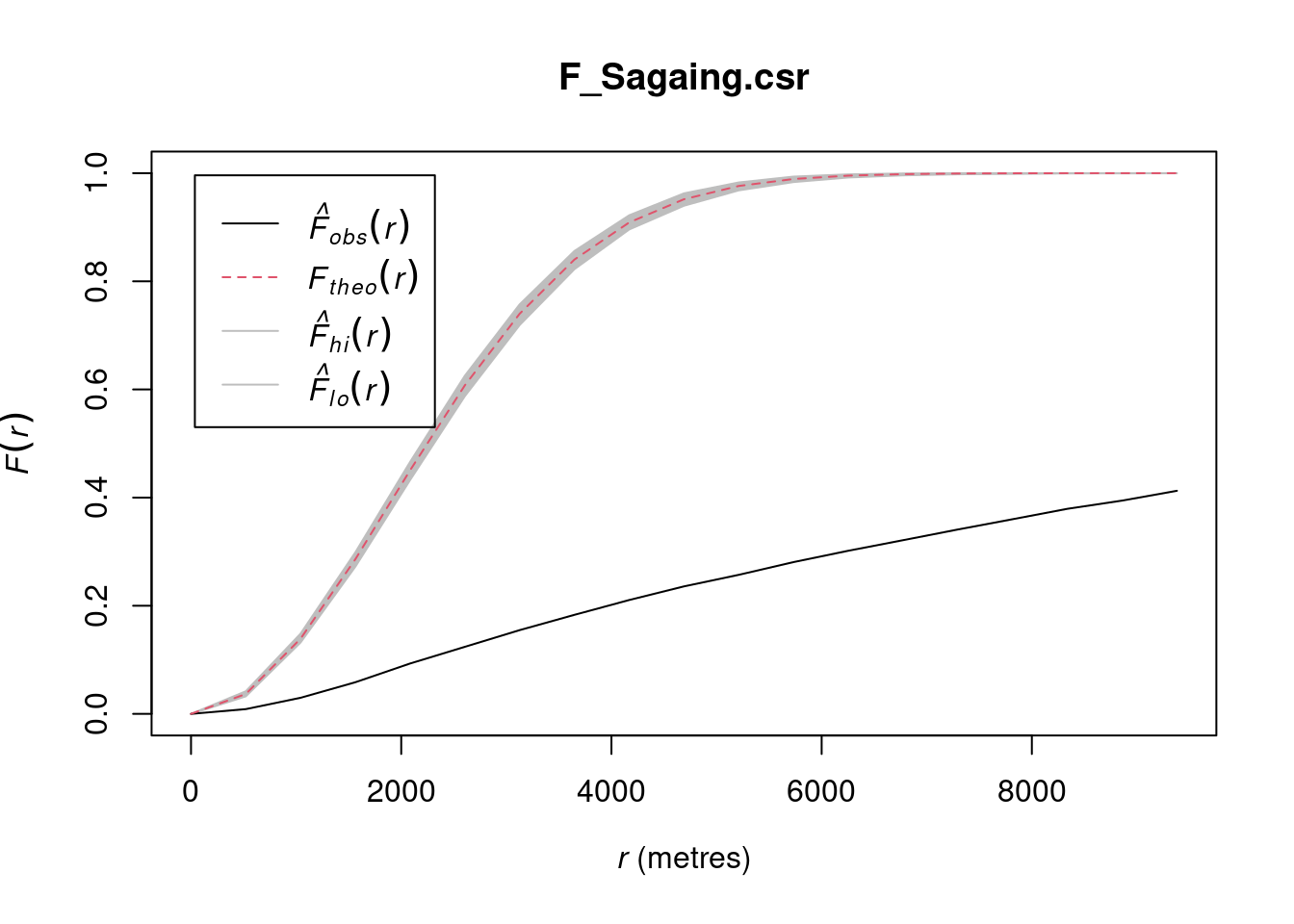
L-Function
The K-function measures the number of events found up to a given distance of any particular event.
It answers the question: “how many additional points are found within a distance r from an average point, compared to what would be expected if the points were randomly distributed”?
The L-function is a transformation of the K-function designed to make it easier to interpret the results of spatial point pattern analysis. The L-function is often used because it linearizes the K-function under the assumption of complete spatial randomness (CSR), making deviations from randomness easier to detect.
Linear Under CSR: Under complete spatial randomness (CSR), the L-function should be approximately equal to the distance r.
Clustering: If the observed is above the line, it indicates clustering at distance
r. There are more points close to each other than expected under CSR.Dispersion: If the observed is below the line, it indicates regularity or dispersion at distance
r. The points are more evenly spaced than expected under CSR.
L_ck = Lest(conflict_data_2022_sagaing_ppp, correction = "Ripley")
plot(L_ck, . -r ~ r,
ylab= "L(d)-r", xlab = "d(m)", xlim=c(0,50000))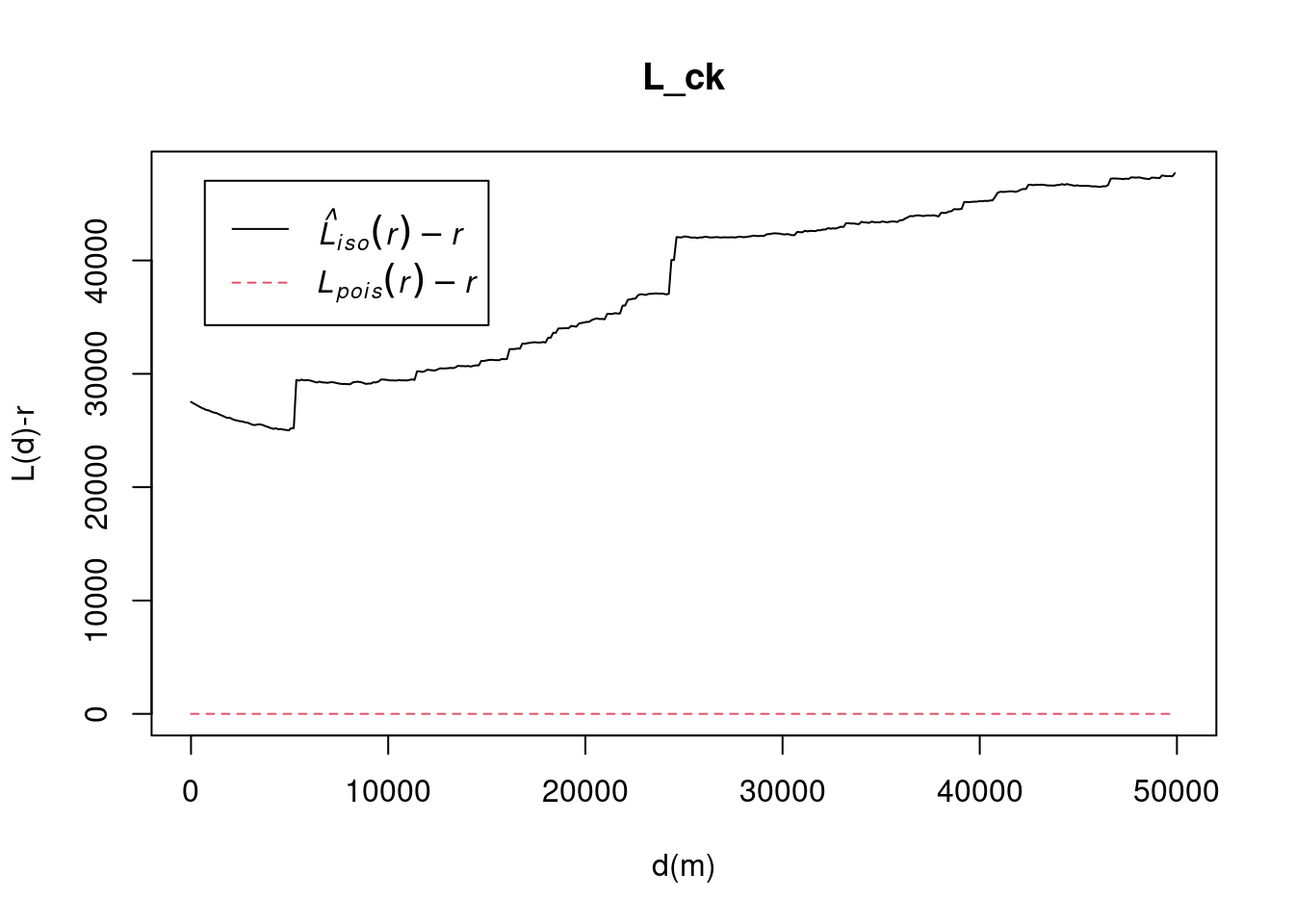
The decrease in the K-function up to 5000 meters suggests point dispersion at smaller distances. The sharp increase at 5000 meters indicates the start of clustering, with local clusters becoming more apparent. The gradual rise between 5000 and 25000 meters reflects increasing clustering across larger areas, possibly indicating regional-scale grouping of points, like towns or strategic locations. The second sharp increase at 25,000 meters suggests larger clusters or groups of clusters, indicating broader patterns in how the points are distributed. Beyond 25,000 meters, clustering continues across even larger distances, pointing to an overall structure where points are organized into regional clusters. Beyond 25000 meters, clustering continues across even larger distances, pointing to an overall structure where points are organized into regional clusters.
The regular spacing up to 5000 meters could be due to geographic barriers or strategic factors preventing clustering. The sharp increase at 5000 meters suggests localized clusters, possibly in towns or military zones, while the second increase at 25000 meters reflects a larger, regional-scale clustering. Beyond 25000 meters, the upward trend indicates that these clusters are part of a broader pattern, with conflict events in different regions still showing interdependence over larger distances.
Hypothesis testing
To confirm the observed spatial patterns above, a hypothesis test will be conducted. The hypothesis and test are as follows:
Ho = The distribution of conflicts at Sagaing are randomly distributed.
H1= The distribution of conflicts at Sagaing are not randomly distributed.
The null hypothesis will be rejected if p-value if smaller than alpha value of 0.001.
L_Sagaing.csr <- envelope(conflict_data_2022_sagaing_ppp, Lest, nsim = 99, rank = 1, glocal=TRUE)Generating 99 simulations of CSR ...
1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20,
21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40,
41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60,
61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80,
81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98,
99.
Done.plot(L_Sagaing.csr, . - r ~ r, xlab="d", ylab="L(d)-r", xlim=c(0,50000))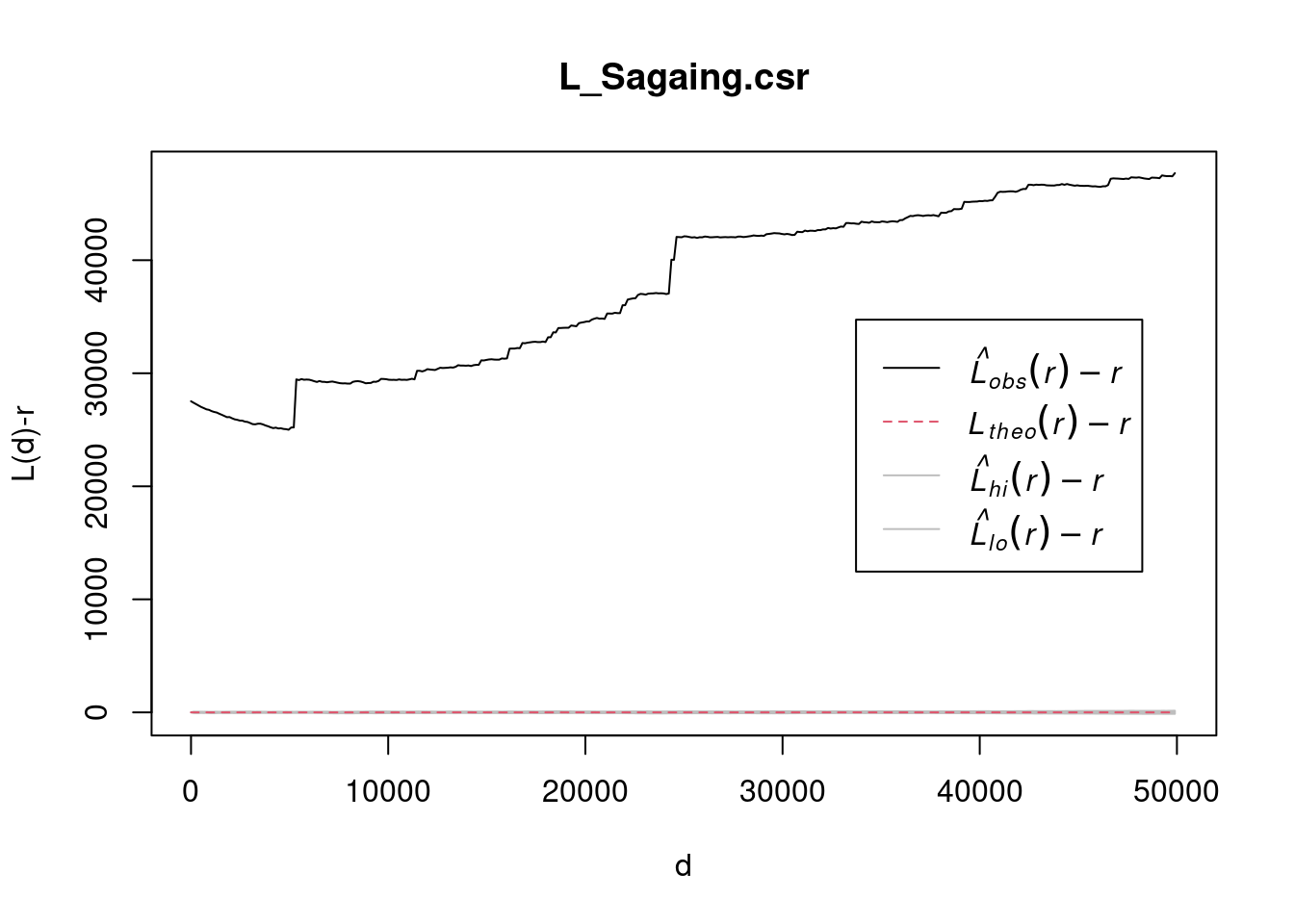
Quarterly spatio-temporal KDE
A spatio-temporal point process (also called space-time or spatial-temporal point process) is a random collection of points, where each point represents the time and location of an event. In this section, we are going to take a deep dive into the conflict occurring at Sagaing.
Import data
townships <- st_read("data", layer = "mmr_polbnda_adm3_250k_mimu_1") %>% st_transform(crs = 32647) %>% filter(ST == "Sagaing")Reading layer `mmr_polbnda_adm3_250k_mimu_1' from data source
`/home/tropicbliss/GitHub/quarto-project/Take-home_Ex/Take-home_Ex01/data'
using driver `ESRI Shapefile'
Simple feature collection with 330 features and 9 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 92.1721 ymin: 9.696844 xmax: 101.17 ymax: 28.54554
Geodetic CRS: WGS 84Plotting out maps
Now, we need to extract out the month from the dates in each conflict and transform it into yearly quarters (from 1 to 4). Take note that we define a custom function called get_quarter to make our lives easier. We then only select out the quarter and the geometry to make quarter the marks value for the as.ppp function to interpret the data correctly.
get_quarter <- function(month) {
return ((month + 2) %/% 3)
}
conflict_quarter <- conflict_data_2022_sagaing %>% mutate(quarter = month(event_date) %>% get_quarter()) %>% dplyr::select(quarter)Creating owin object
We first convert the conflict_quarter dataset into a ppp using the as.ppp function. The ppp object represents a point pattern, which includes the locations of conflict events and which quarter each conflict took place. We then convert the townships dataset into an observation window (owin) using the as.owin function. An owin object defines a spatial window, i.e., the region of interest where spatial analysis is performed (in this case, the township boundaries).
conflict_quarter_ppp <- rescale(as.ppp(conflict_quarter), s = 1000, unitname = c("km", "kilometers"))
townships_owin <- rescale(as.owin(townships), s = 1000, unitname = c("km", "kilometers"))
combined_owin <- conflict_quarter_ppp[townships_owin]Calculating STKDE
We then use spattemp.density from the sparr library to perform a spatio-temporal kernel density estimation (KDE). This would estimate how the density of the events (like conflicts) changes over both space and time, smoothing the point pattern (combined_owin) using a kernel function.
st_kde <- spattemp.density(combined_owin)Calculating trivariate smooth...Done.
Edge-correcting...Done.
Conditioning on time...Done.Plotting the results
We then create a multi-panel plot layout and visualise spatio-temporal kernel density estimation (KDE) results across different time intervals, while overlaying township boundaries and labeling them on each plot. This allows us to better analyse conflict hotspots in detail.
# Convert townships to sf object (if not already in sf format)
townships_sf <- st_as_sf(townships)
# Set tmap mode to "view" to display interactive maps in Quarto
tmap_mode("view")tmap mode set to interactive viewing# Loop through the quarters and display KDE for each time slice
tims <- 1:4 # Time indices corresponding to each quarter
for (i in tims) {
# Extract the spatial KDE slice for the i-th quarter
kde_slice <- st_kde$z[[i]] # Assuming st_kde has a list of rasters for each time step
# Convert KDE slice to RasterLayer
kde_raster <- raster(kde_slice)
# Ensure the raster has correct extent and CRS
extent(kde_raster) <- st_bbox(townships_sf) # Set bounding box to match townships
crs(kde_raster) <- st_crs(townships_sf)$proj4string # Match CRS
# Create the tmap plot
tm <- tm_shape(kde_raster) +
tm_raster("layer", title = paste("KDE at quarter", i), style = "cont", legend.show = TRUE, alpha = 0.7) + # KDE layer
# Add township borders
tm_shape(townships_sf) +
tm_borders(col = "black", lwd = 1) +
# Add township labels at centroids
tm_text("TS", size = 0.5, col = "blue") +
# Overlay OpenStreetMap as the basemap
tm_basemap(server = "OpenStreetMap") +
# Layout settings
tm_layout(main.title = paste("KDE at quarter", i), legend.outside = TRUE)
# Print the map to display it in Quarto
print(tm)
}
tmap_mode("plot")tmap mode set to plottingIn quarter 1, conflict is mainly situated around the township of Salingyi, with smaller pockets around Kale and at the meeting point of Tabayin and Khin-U. Salingyi is home to the controversial Letpadaung copper mine, a frequent site of protests and conflict due to land disputes and environmental issues. Its economic significance and military ties make it a target for insurgents. Sagaing has been a key resistance area against the military junta, especially after the 2021 coup, with People’s Defense Forces (PDFs) and ethnic armed groups active in the region. Kale and the Tabayin-Khin-U area are known resistance centers, with smaller conflicts likely linked to local PDFs and clashes with military forces.
Sagaing Region, largely Bamar, borders Chin and Shan states, contributing to tensions from neighboring ethnic conflicts. Local grievances, like land rights issues, may have fueled resistance in Salingyi, while the Tabayin-Khin-U area is strategic for transportation routes, crucial for both the military and insurgents. Sagaing’s terrain favors insurgents, allowing for sustained clashes, especially near Kale, close to Chin State’s conflict zones. The Myanmar military likely targeted these areas due to their strategic importance and the presence of resistance forces.
In quarter 2, conflict around the Tabayin-Khin-U region died down. In quarter 3, the conflict at Kale and Salingyi seems to be dying down, but in quarter 4 it flared back up again, but thankfully we have not seen a dramatic resurgance at Kale. Smaller scale conflicts have also started to flare up around Sagaing and Wetlet townships. In Sagaing and Wetlet townships, smaller-scale conflicts suggest the spread of insurgency tactics. Mobile groups of PDFs may be using hit-and-run tactics or localized skirmishes, particularly where the military is stretched thin. Resistance forces could be shifting to smaller engagements across a broader area, targeting government forces or infrastructure.
Animating the conflict in Sagaing for 2022
Just for curiosity’s sake, we are also going to analyse the trajectory of the conflict in detail via an animation by bringing in the animation library which creates a GIF and embeds it on this HTML page.
We are going to extract the week number for each conflict from 1 to 52 (2022 is not a leap year so it is not 53). We then only select the week and the geometry in the SFO such that it will choose the correct marks value. Next, we convert it first to a ppp object and then to an owin object as per usual. We combine the points and the geometry, calculate STKDE, and plot a separate graph for each week.
The reason why I used weeks and not days is that the data we have does not track how long a conflict occurs. Hence according to our maps, a conflict could be reported one day and gone at the next, which could be misleading. Using weeks instead of days makes it less granular.
Note that eval is set to false since saveGIF requires the imagemagick system library and not every computer has it installed.
pacman::p_load(animation)
conflict_week <- conflict_data_2022_sagaing %>% mutate(week = week(event_date)) %>% dplyr::select(week)
conflict_week_ppp <- as.ppp(conflict_week)
townships_owin <- as.owin(townships)
combined_owin <- conflict_week_ppp[townships_owin]
st_kde <- spattemp.density(combined_owin)
saveGIF({
tims <- 1:52
for(i in tims){
plot(st_kde, i, override.par=FALSE, fix.range=TRUE, main=paste("KDE at week",i))
plot(st_geometry(townships), add=TRUE)
text(st_coordinates(suppressWarnings(st_centroid(townships))), labels=townships$TS, col="white")
}
}, movie.name = "myanmar_conflict.gif", interval = 0.5, nmax = 30, ani.width = 1920, ani.height = 1080)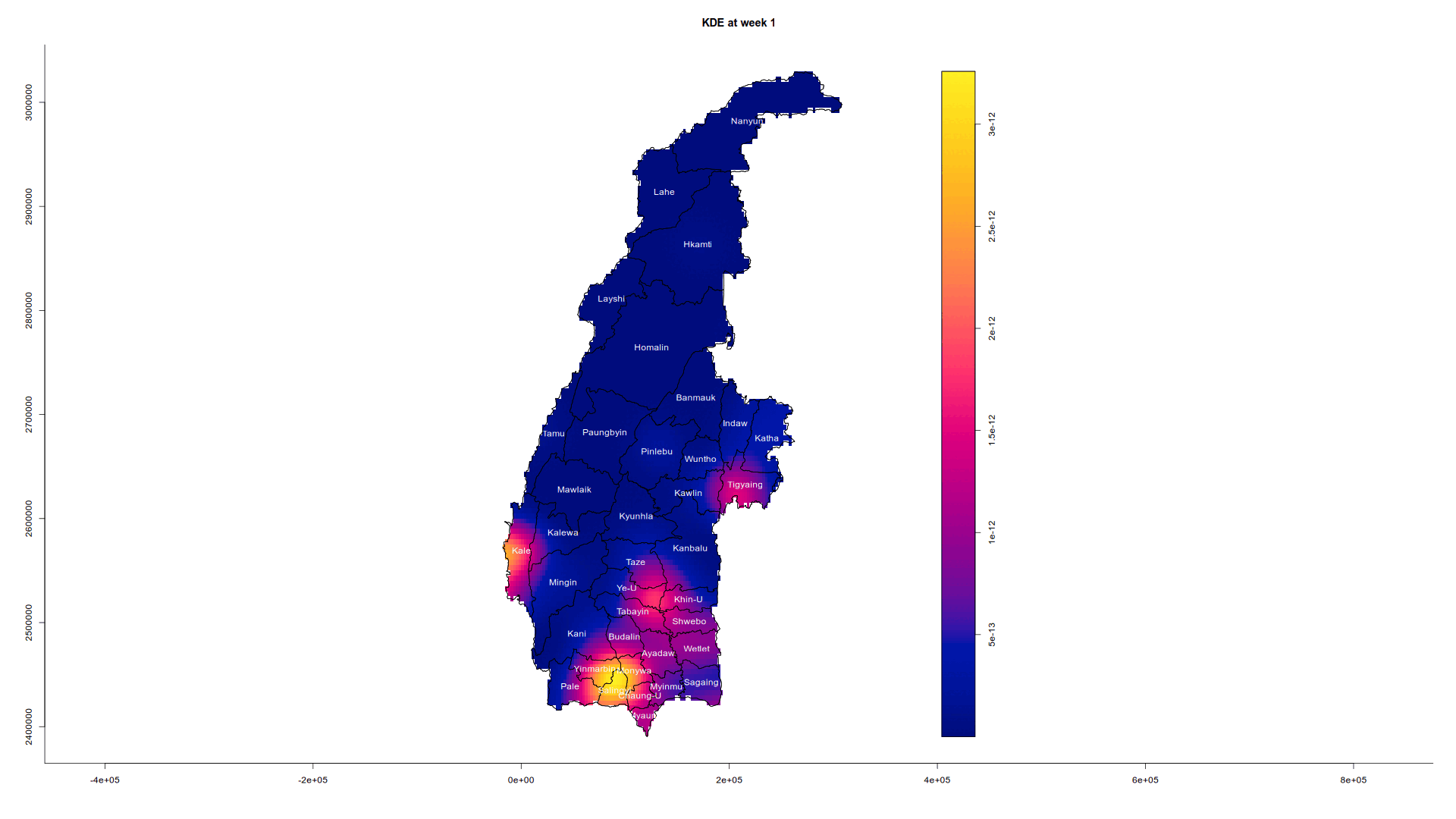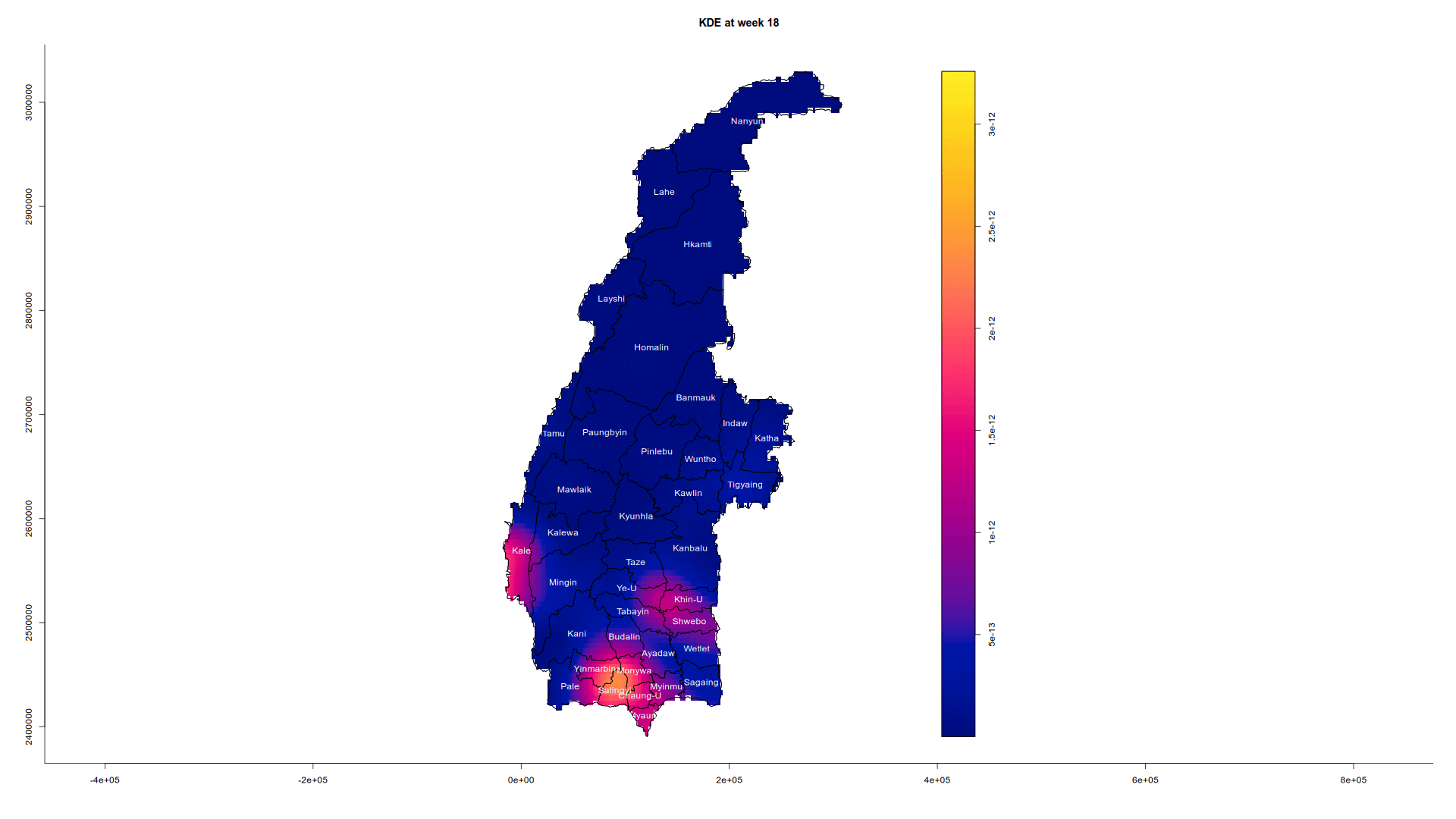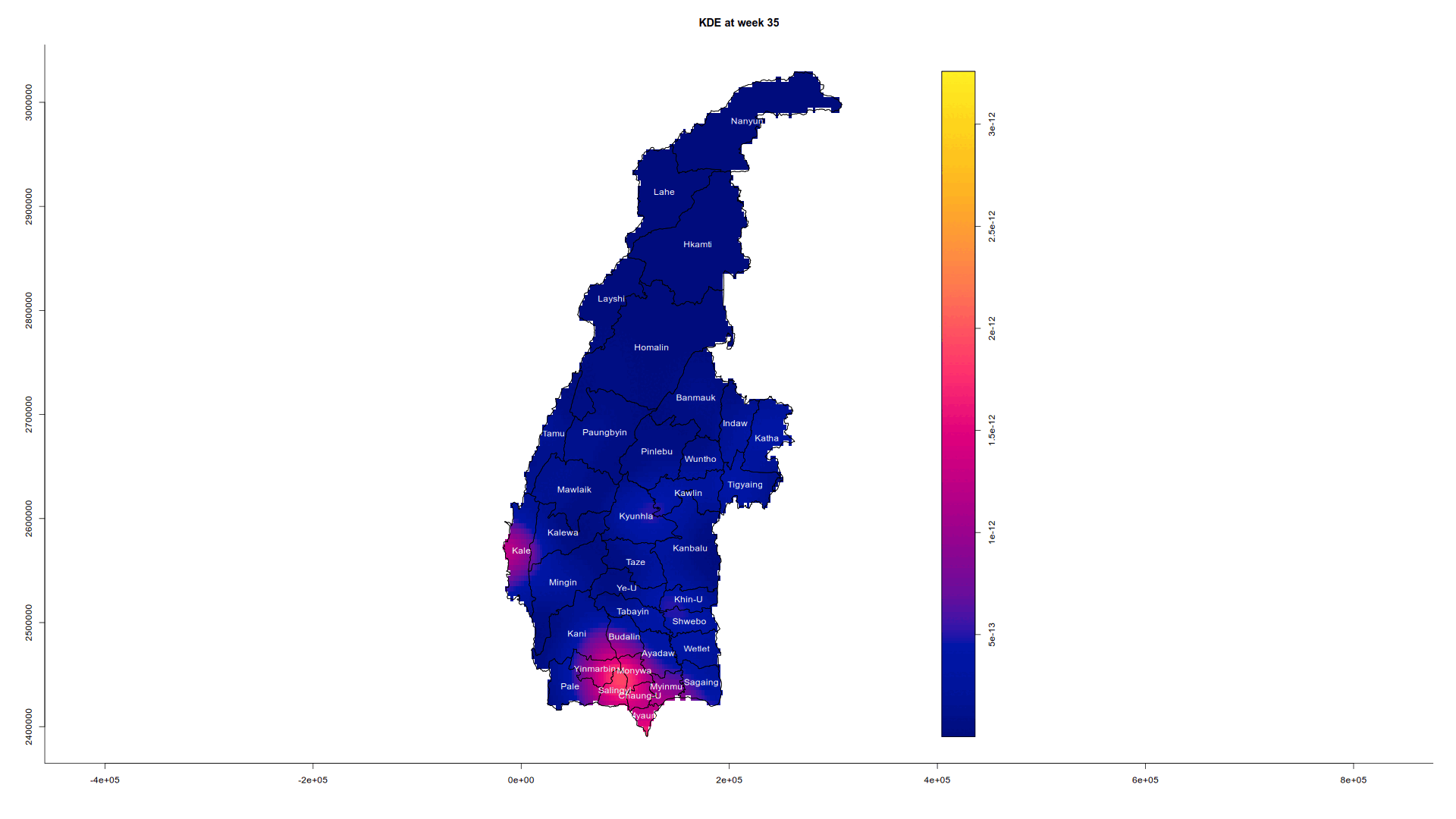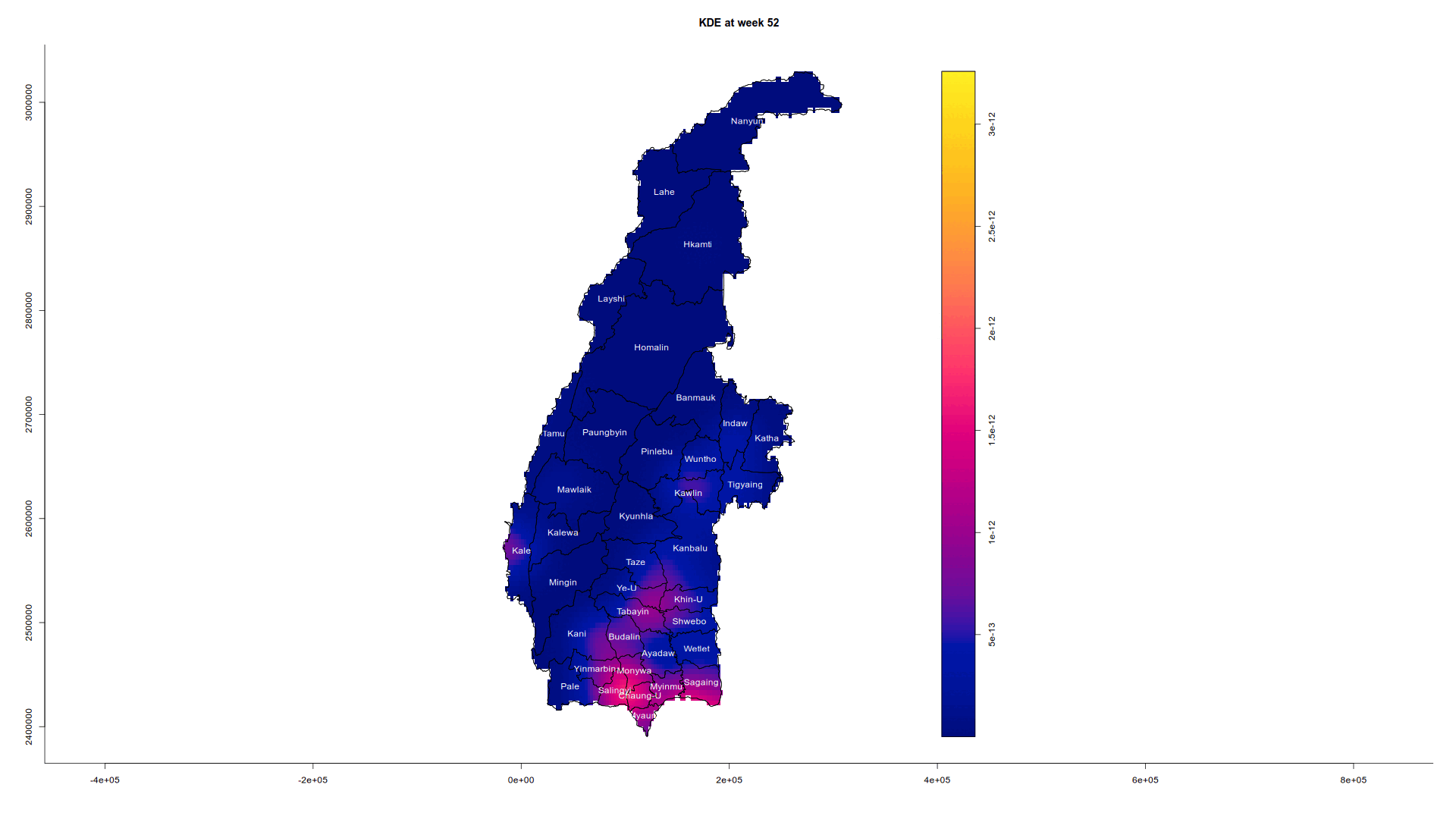
2nd Order Spatio-temporal Point Patterns Analysis
Now let’s shift our attention to Yangon. Yangon is the largest city in Myanmar and it would be interesting to find out the relationship between the road networks in the city and conflict events. We could have used the official network data from MIMU, but I personally feel that there is not enough information to give us an accurate representation.
yangon_bounds <- boundaries %>% filter(ST == "Yangon")
railways <- st_read("data", layer = "mmr_rlwl_250k_mimu_1") %>% st_transform(crs = 32647) %>% filter(Div_Name == "Yangon")Reading layer `mmr_rlwl_250k_mimu_1' from data source
`/home/tropicbliss/GitHub/quarto-project/Take-home_Ex/Take-home_Ex01/data'
using driver `ESRI Shapefile'
Simple feature collection with 76 features and 7 fields
Geometry type: LINESTRING
Dimension: XY
Bounding box: xmin: 93.9824 ymin: 13.80667 xmax: 98.26597 ymax: 25.44297
Geodetic CRS: WGS 84railways <- st_intersection(railways, yangon_bounds) %>% st_cast("LINESTRING")Warning: attribute variables are assumed to be spatially constant throughout
all geometriesWarning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring onlyrivers <- st_read("data", layer = "myanmar_river_network_250k") %>% st_transform(crs = 32647)Reading layer `myanmar_river_network_250k' from data source
`/home/tropicbliss/GitHub/quarto-project/Take-home_Ex/Take-home_Ex01/data'
using driver `ESRI Shapefile'
Simple feature collection with 60 features and 4 fields
Geometry type: LINESTRING
Dimension: XY
Bounding box: xmin: 92.17393 ymin: 9.939526 xmax: 99.18699 ymax: 27.7137
Geodetic CRS: WGS 84rivers <- st_intersection(rivers, yangon_bounds) %>% st_cast("LINESTRING")Warning: attribute variables are assumed to be spatially constant throughout
all geometries
Warning: keeping first linestring only
Warning: keeping first linestring only
Warning: keeping first linestring onlytmap_mode("view")tmap mode set to interactive viewingtm_shape(rivers) +
tm_lines()tm_shape(railways) +
tm_lines()tmap_mode("plot")tmap mode set to plottingImporting data
yangon_bounds <- boundaries %>% filter(ST == "Yangon")
class(yangon_bounds)[1] "sf" "data.frame"Now let’s bring in an extra dependency, spNetwork which is going to help us calculate network KDE.
Network KDE (NKDE) is essentially a variation of KDE that applies to events occuring alongside networks like roads or railways. With NKDE, we can calculate and visualise the density of events happening right alongside networks.
pacman::p_load(spNetwork)Data importing
Now that we are done with the import, we are going to filter conflict data to look for conflicts that happened in 2022 and in Yangon.
conflict_data_2022 <- conflict_data %>% filter(year == 2022 & admin1 == "Yangon")Now that we have conflict points, let’s bring in the road network data.
roads <- st_read("data", layer = "gis_osm_roads_free_1") %>% st_transform(crs = 32647)Reading layer `gis_osm_roads_free_1' from data source
`/home/tropicbliss/GitHub/quarto-project/Take-home_Ex/Take-home_Ex01/data'
using driver `ESRI Shapefile'
Simple feature collection with 566089 features and 10 fields
Geometry type: LINESTRING
Dimension: XY
Bounding box: xmin: 92.13721 ymin: 9.783255 xmax: 101.2285 ymax: 28.37868
Geodetic CRS: WGS 84Take note that the amount of data we are working with is extremely large, so you will need a good PC for this. To expedite this, we are only going to take a small subset of roads into account. Trust me, this is mandatory.
roads <- roads %>% filter(!is.na(name))Data wrangling
Notice that we have imported the network for the entire Myanmar. To keep it within Yangon, we are going to use st_intersection to chop off any parts of the network that is not within the state.
roads <- roads %>% st_intersection(yangon_bounds)Warning: attribute variables are assumed to be spatially constant throughout
all geometriesglimpse(st_geometry(roads))sfc_GEOMETRY of length 12126; first list element: 'XY' num [1:2, 1:2] 195300 195277 1856849 1856858Just by using st_intersection, we get back an sfc_GEOMETRY object (full of MultiLineStrings), whilst what we want is sfc_LINESTRING.
roads <- roads %>% st_cast("LINESTRING", do_split = TRUE)Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring only
Warning in st_cast.MULTILINESTRING(X[[i]], ...): keeping first linestring onlyWe use do_split here to ensure that MultiLineStrings are properly cast to LineStrings while preserving the line’s curvature, as lixelize_lines cannot work with MultiLineStrings properly.
Calculating NKDE
We first have to calculate lixels and samples.
What are lixels? Well, you can think of lixels as individual segments of a line of fixed length. It is useful for calculating density estimation along a network. This together with samples, which represent locations where the kernel density is calculated can give us a nice visualisation of density along a network.
lixels_roads <- lixelize_lines(roads, 700, mindist = 375)
samples_roads <- lines_center(lixels_roads)There are many knobs we can configure here. The nkde function calculates the density of point events along a network. This method is used for analyzing spatial data constrained by a network to understand how events are distributed along these networks.
bw: The kernel’s bandwidth determines the spatial extent over which events affect the density calculation. A larger bandwidth produces a smoother density estimate over a wider area, while a smaller bandwidth leads to more localized density values. However, reducing the bandwidth too much can make the plot appear “noisy” or fragmented.
div: This parameter specifies how the density is normalized. When set to bw, the bandwidth is used for normalization, ensuring that density values remain comparable even if the bandwidth changes.
method: This defines the approach used for kernel density calculation. The simple method is the default, providing a straightforward kernel density estimation without additional complexity or refinement.
max_depth: This controls how far the algorithm searches within the network to find neighboring points when estimating density. Increasing this value allows the algorithm to consider more distant points, which raises computation time. Reducing the agg parameter can make the algorithm more responsive to smaller event clusters but may introduce noise into the results.
agg: This parameter determines the level of aggregation applied to the density results. A lower value results in finer, less aggregated estimates, while a higher value groups results over larger areas, providing a coarser density estimate. Lowering the agg parameter (which controls aggregation in the estimation) will make the algorithm more sensitive to smaller clusters of events, but it might also introduce noise.
densities_roads <- nkde(roads,
events = conflict_data_2022,
w = rep(1, nrow(conflict_data_2022)),
samples = samples_roads,
kernel_name = "quartic",
bw = 300,
div= "bw",
method = "simple",
digits = 1,
tol = 1,
grid_shape = c(1,1),
max_depth = 8,
agg = 5,
sparse = TRUE,
verbose = FALSE)Now, we need to scale the density in such a way that it can be rendered by tmap.
samples_roads$density <- densities_roads
lixels_roads$density <- densities_roads
samples_roads$density <- samples_roads$density * 1000
lixels_roads$density <- lixels_roads$density * 1000To save on HTML rendering time, the interactive map will be hosted in a separate HTML in which you will find the link below.
tmap_mode('view')
map <- tm_shape(lixels_roads)+
tm_lines(col="density")+
tm_shape(conflict_data_2022)+
tm_dots()
tmap_save(map, "map1.html")
tmap_mode('plot')As you can see, the main cluster of conflicts occur at Downtown Yangon. Many of these conflicts were triggered by homemade explosives made by guerrilla groups. As urban warfare became impractical, resistance forces shifted to targeting SAC-aligned officials, with 367 SAC-appointed officials assassinated between February 2021 and February 2022. Resistance also targeted the homes of SAC pilots in Yangon in retaliation for airstrikes on civilians. In September 2022, anti-SAC guerillas assassinated retired Brigadier General Ohn Thwin, mentor to SAC vice-chairman Soe Win, prompting increased security for top SAC officials.
distance_matrix <- st_distance(conflict_data_2022)
distance_matrix_numeric <- as.numeric(distance_matrix) # remove the units, or mean() will start complaining
average_distance <- base::mean(as.numeric(distance_matrix_numeric[distance_matrix_numeric > 0])) # excluding the diagonal, which is 0
average_distance / 1000[1] 16.81996The density shown in the map is really not high, given the large geographical area of Yangon. Even when it looks like it is clustered from afar, they are really not that near from one another. As you can see, each point is on average 16.8 km away from each other.
But even from that, we can clearly see that the conflicts cluster around human settlements (especially around Downtown Yangon), and hence near roadways.
tmap_mode("view")
map <- tm_basemap(server = "OpenStreetMap") +
tm_shape(conflict_data_2022) +
tm_dots(col = "sub_event_type",
palette = "Set1",
size = 0.1,
title = "Conflict Types") +
tm_shape(roads) +
tm_lines()
tmap_save(map, filename = "map2.html")
tmap_mode("plot")There is a huge cluster of conflicts in Downtown Yangon corresponding with remove explosives or IEDs. There is also a tinier cluster of arrests west of Yangon. On 31 May 2022, a bombing near Sule Pagoda in Yangon killed one and injured nine. State media blamed the People’s Defence Force, which denied involvement.
Conclusion
The geospatial analysis of the Myanmar conflict from January 2021 to June 2024 reveals key patterns in the distribution of violence. Focusing on Battles, Explosion/Remote violence, Strategic developments, and Violence against civilians, Kernel Density Estimation (KDE) highlighted intense conflict clustering in Rakhine, Chin, Sagaing, and Kayah states.
While regions like Yangon and Shan (South)/Kayah experienced temporary reductions in violence, they saw a resurgence in later periods. The conflict’s spread into Tanintharyi and Sagaing suggests an escalation into previously less-affected areas. Yangon saw sporadic but notable bursts of violence, reflecting evolving urban warfare and insurgent tactics.
Overall, the spatial analysis underscores the complexity of the conflict, with violence intensifying in certain areas while abating in others. The regional variation in conflict dynamics highlights the importance of localized peacebuilding efforts and strategic responses tailored to each area’s unique conflict drivers. The results provide valuable insights into how the conflict is evolving and the geographic factors influencing its trajectory, offering a foundation for more targeted humanitarian interventions, security responses, and conflict resolution efforts in Myanmar.